Dimostrazione di una possibile spiegazione.
Crea script tabella
SELECT *
INTO #T
FROM master.dbo.spt_values
CREATE NONCLUSTERED INDEX [IX_T] ON #T ([name] DESC,[number] DESC);
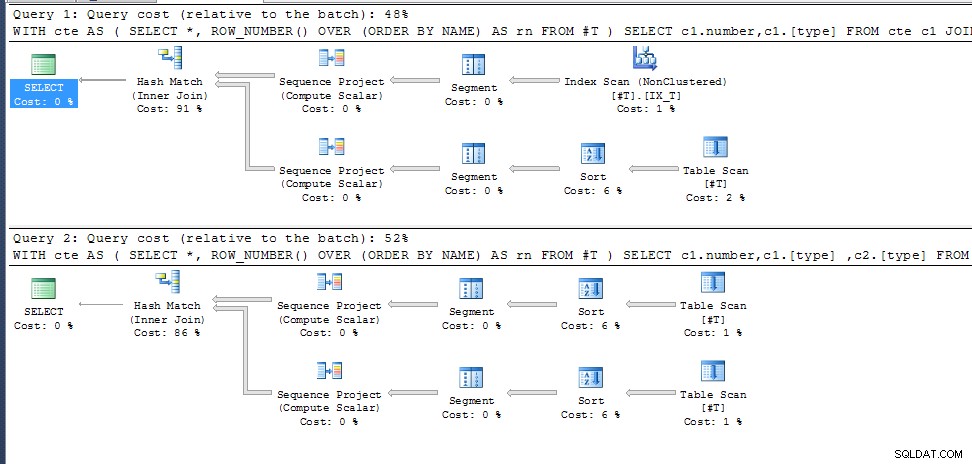
Query uno (restituisce 35 risultati)
WITH cte AS
(
SELECT *, ROW_NUMBER() OVER (ORDER BY NAME) AS rn
FROM #T
)
SELECT c1.number,c1.[type]
FROM cte c1
JOIN cte c2 ON c1.rn=c2.rn AND c1.number <> c2.number
Query due (come prima ma aggiungendo c2.[tipo] all'elenco di selezione si ottengono 0 risultati);
WITH cte AS
(
SELECT *, ROW_NUMBER() OVER (ORDER BY NAME) AS rn
FROM #T
)
SELECT c1.number,c1.[type] ,c2.[type]
FROM cte c1
JOIN cte c2 ON c1.rn=c2.rn AND c1.number <> c2.number
Perché?
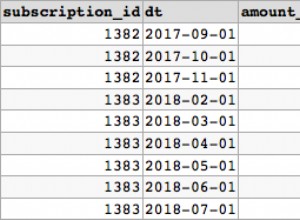
row_number() per i NAME duplicati non è specificato, quindi sceglie semplicemente quello che si adatta al miglior piano di esecuzione per le colonne di output richieste. Nella seconda query questo è lo stesso per entrambe le invocazioni di cte, nella prima sceglie un percorso di accesso diverso con una diversa numerazione_riga risultante.
Soluzione suggerita
Ti stai unendo automaticamente al CTE su ROW_NUMBER() over (order by t.[Date])
Contrariamente a quanto ci si poteva aspettare, il CTE probabilmente non essere materializzato
che avrebbe assicurato la coerenza per l'auto join e quindi si presume una correlazione tra ROW_NUMBER() su entrambi i lati che potrebbero non esistere per i record in cui è duplicato un [Date] esiste nei dati.
Cosa succede se provi ROW_NUMBER() over (order by t.[Date], t.[id]) per garantire che, in caso di date vincolate, row_numbering sia in un ordine coerente garantito. (O qualche altra colonna/combinazione di colonne che può differenziare i record se id non lo farà)