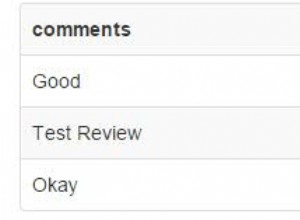
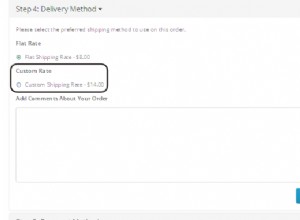
Su un tavolo di prova la mia parte il tuo piano originale appare come segue.
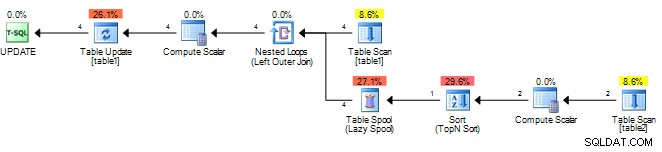
Calcola solo il risultato una volta e lo memorizza nella cache in uno sppol, quindi riproduce quel risultato. Puoi provare quanto segue in modo che SQL Server consideri la sottoquery correlata e necessiti di una rivalutazione per ogni riga esterna.
UPDATE table1
SET table2Id = (SELECT TOP 1 table2Id
FROM table2
ORDER BY Newid(),
table1.table1Id)
Per me che dà questo piano senza la bobina.
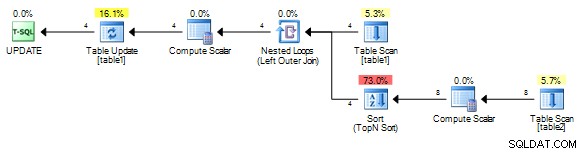
È importante correlare su un campo univoco da table1 tuttavia in modo che anche se viene aggiunta una bobina, deve sempre essere rimbalzata anziché riavvolta (riproducendo l'ultimo risultato) poiché il valore di correlazione sarà diverso per ogni riga.
Se le tabelle sono grandi, questo sarà lento poiché il lavoro richiesto è un prodotto delle due righe della tabella (per ogni riga in table1 deve eseguire una scansione completa di table2 )