Cosa fa sì che la query di applicazione incrociata funzioni così male su questo semplice documento XML e che funzioni in modo esponenzialmente più lento man mano che il set di dati cresce?
È l'uso dell'asse padre per ottenere l'ID attributo dal nodo dell'elemento.
È questa parte del piano di query che è problematica.

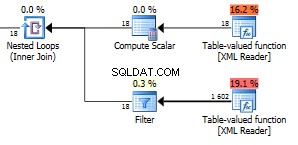
Nota le 423 righe che escono dalla funzione con valori di tabella inferiore.
L'aggiunta di un solo nodo elemento in più con tre nodi campo ti dà questo.
732 righe restituite.
E se raddoppiamo i nodi dalla prima query per un totale di 6 nodi elemento?
Abbiamo fino a un'enorme riga 1602 restituita.
La figura 18 nella funzione in alto rappresenta tutti i nodi di campo nell'XML. Abbiamo qui 6 articoli con tre campi in ogni articolo. Questi 18 nodi vengono utilizzati in un loop nidificato che si unisce all'altra funzione, quindi 18 esecuzioni che restituiscono 1602 righe danno che restituisce 89 righe per iterazione. Questo sembra essere il numero esatto di nodi nell'intero XML. Bene, in realtà è uno in più di tutti i nodi visibili. non so perché. Puoi utilizzare questa query per controllare il numero totale di nodi nel tuo XML.
select count(*)
from @XML.nodes('//*, //@*, //*/text()') as T(X)
Quindi l'algoritmo utilizzato da SQL Server per ottenere il valore quando si utilizza l'asse padre .. in una funzione valori è che trova prima tutti i nodi su cui stai distruggendo, 18 nell'ultimo caso. Per ciascuno di questi nodi distrugge e restituisce l'intero documento XML e controlla nell'operatore di filtro il nodo che si desidera effettivamente. Ecco la tua crescita esponenziale. Invece di usare l'asse genitore dovresti usare un'applicazione incrociata in più. Distruggi prima sull'oggetto e poi sul campo.
select I.X.value('@name', 'varchar(5)') as item_name,
F.X.value('@id', 'uniqueidentifier') as field_id,
F.X.value('@type', 'int') as field_type,
F.X.value('text()[1]', 'nvarchar(15)') as field_value
from #temp as T
cross apply T.x.nodes('/data/item') as I(X)
cross apply I.X.nodes('field') as F(X)
Ho anche cambiato il modo in cui accedi al valore del testo del campo. Usando . farà in modo che SQL Server cerchi i nodi figlio in field e concatenare quei valori nel risultato. Non hai valori figlio, quindi il risultato è lo stesso ma è una buona cosa evitare di avere quella parte nel piano di query (l'operatore UDX).
Il piano di query non presenta il problema con l'asse padre se stai utilizzando un indice XML, ma potrai comunque trarre vantaggio dalla modifica del modo in cui recuperi il valore del campo.