Panoramica dell'indice di SQL Server
Quando si parla dell'ottimizzazione delle prestazioni di SQL Server e del miglioramento delle query, la prima cosa da considerare è l'indice di SQL Server. Serve ad accelerare la lettura dei dati dalle tabelle sottostanti fornendo un rapido accesso alle righe richieste. Pertanto, non sarà necessario scansionare tutti i record della tabella.
L'indice di SQL Server fornisce quelle funzionalità di ricerca rapida grazie alla struttura B-Tree dell'indice. Questa struttura consente di spostarsi rapidamente tra le righe della tabella in base alla chiave di indice e di recuperare immediatamente i record richiesti. Non sarà necessario leggere l'intera tabella.
Tipi di indici di SQL Server
Tra le tipologie principali, prestiamo attenzione agli indici cluster e non cluster.
L'indice cluster ordina i dati effettivi nelle pagine di dati in base ai valori della chiave dell'indice cluster. Memorizza i dati a livello di "foglia" dell'indice, garantendo la possibilità di creare un solo indice cluster su ciascuna tabella. L'indice cluster viene creato automaticamente quando nella tabella heap viene visualizzato un vincolo di chiave primaria.
L'indice non cluster contiene il valore della chiave dell'indice e un puntatore al resto delle colonne di riga nella tabella principale. È il livello "foglia" dell'indice, con la possibilità di creare fino a 999 indici non raggruppati su ogni tabella.
Se la tua tabella non ha un indice cluster creato su di essa, la tabella viene chiamata "tabella heap". Tale tabella non ha criteri per specificare l'ordine dei dati all'interno delle pagine e l'ordinamento e il collegamento delle pagine.
Quando viene creato un indice cluster su quella tabella, chiamiamo la tabella ordinata una tabella cluster.
Esistono anche altri tipi di indici forniti da SQL Server:
- L'indice Unique impone l'univocità dei valori della colonna;
- L'indice di copertura contiene tutte le colonne richieste dalla query;
- L'indice composto contiene più colonne nella chiave dell'indice;
- Altri tipi di indici particolari sono gli indici XML, Spatial e Columnstore.
Il vantaggio dell'indice di SQL Server è che migliora le prestazioni delle query. Tuttavia, funziona se solo l'indice è corretto. In caso contrario, influirà negativamente sulle prestazioni delle query e consumerà le risorse di SQL Server per archiviare e mantenere indici inutili.
Scegliere il miglior indice che risolva tutti i problemi non è un compito facile. L'aggiunta di un nuovo indice può accelerare il processo di recupero dei dati, ma rallenta i processi di modifica dei dati. Qualsiasi modifica apportata alla tabella sottostante viene applicata direttamente a tutti gli indici correlati per mantenere i dati coerenti.
Ecco perché dovresti studiare e testare l'impatto del nuovo indice prima di crearlo nell'ambiente di produzione. È inoltre necessario monitorarne l'impatto e l'utilizzo dopo averlo distribuito nell'ambiente di produzione.
Fattori da considerare quando si progetta un nuovo indice di SQL Server
Il primo fattore è il tipo di carico di lavoro del database . Supponiamo di avere a che fare con un carico di lavoro OLTP con un gran numero di operazioni di scrittura. Richiede il minor numero possibile di indici. Un altro caso è un carico di lavoro OLAP con molte operazioni di lettura:richiederà il maggior numero possibile di indici per accelerare il recupero dei dati.
Inoltre, devi guardare le dimensioni della tabella . SQL Server Engine preferisce analizzare direttamente la tabella sottostante, invece di sprecare tempo e risorse nella scelta dell'indice migliore per il recupero dei dati da quella piccola tabella.
Dopo aver deciso di creare un indice su quella tabella, devi identificare il tipo di indice per servire la tua query . Lì, specifichi le colonne aggiunte alla chiave di indice. Le basi sono il tipo di dati della colonna e la posizione nei predicati della query e nelle condizioni di unione.
Questi fattori dovrebbero garantire le migliori prestazioni di recupero dei dati, nell'ordine corretto, e mantenere l'indice il più breve e semplice possibile.
Un altro fattore da considerare quando si progetta un nuovo indice è la archiviazione dell'indice . Si consiglia di creare indici non in cluster su un filegroup e un'unità disco separati. In questo modo si isolano le operazioni di I/O eseguite nelle pagine dei dati dell'indice dai file dei dati del database.
Prendi in considerazione la possibilità di impostare l'indice FILFACTOR , che determina la percentuale di spazio su ciascuna pagina a livello di foglia piena di dati (il valore è diverso dallo 0 o 100 percento predefinito). L'obiettivo è lasciare spazio in ogni pagina di dati dell'indice per i record appena inseriti o aggiornati. Inoltre, riduce al minimo l'occorrenza di divisione delle pagine che potrebbe causare il problema di frammentazione dell'indice.
Gestione dell'indice
Il ruolo dell'amministratore del database nel migliorare le prestazioni delle query con gli indici di SQL Server non si limita alla creazione dell'indice. È necessario monitorare in modo proattivo l'utilizzo dell'indice per identificarne la qualità. Inoltre, dobbiamo mantenere l'indice regolarmente per risolvere i problemi di frammentazione.
SQL Server Management Studio, con la sua solida funzionalità di reporting, fornisce i dati statistici più utili agli amministratori di database. Uno di questi rapporti integrati è Statistiche sull'utilizzo dell'indice :
Il rapporto Statistiche sull'utilizzo dell'indice descrive come vengono utilizzati gli indici del database sotto forma di:
- Cerca :il numero di volte in cui l'indice viene utilizzato da SQL Engine per trovare una riga specifica.
- Scansioni :il numero di volte in cui le pagine foglia dell'indice vengono scansionate dal motore SQL.
- Ricerche :il numero di volte in cui un indice non cluster è stato utilizzato come indice cluster per recuperare il resto delle colonne non elencate nell'indice non cluster.
- Aggiornamenti :il numero di volte in cui i dati dell'indice vengono modificati.
Tieni presente che lo scopo principale della creazione dell'indice è eseguire un'operazione di ricerca dell'indice, come mostrato di seguito:
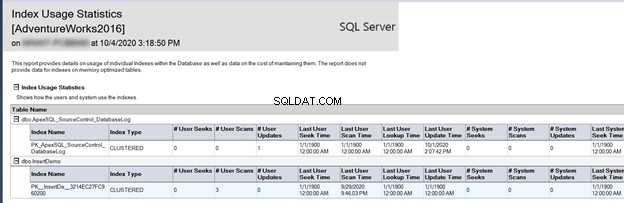
Il report precedente aiuta in modo significativo a specificare se SQL Server sfrutta questi indici per accelerare o meno il processo di recupero dei dati. Se risulta che un determinato indice non funziona come dovrebbe, eliminalo e sostituiscilo con uno migliore.
Il secondo rapporto fornito dall'SSMS è l'Index Physical Statistics . Restituisce le informazioni statistiche sulla percentuale di frammentazione dell'indice per ciascuna partizione di indice, con il numero di pagine su ciascuna partizione di indice.
Consiglia inoltre come risolvere i problemi di frammentazione dell'indice ricostruendo o riorganizzando quell'indice, in base alla percentuale di frammentazione, come mostrato di seguito:
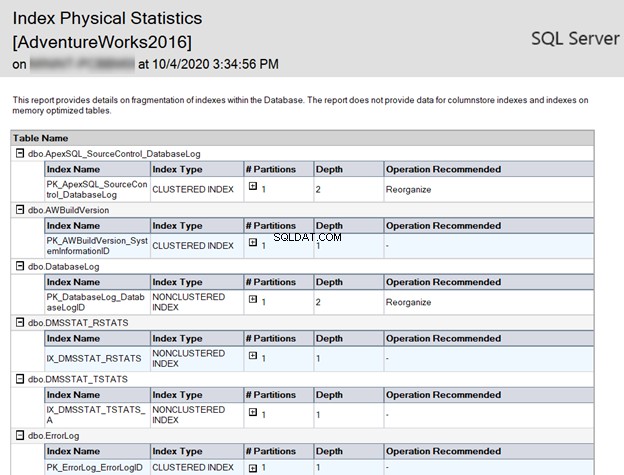
Per applicare i consigli forniti dal report, è possibile eseguire il comando di deframmentazione dell'indice per ciascun indice. Oppure puoi creare un piano di manutenzione utilizzando SSMS per mantenere l'indice nel modo migliore.
Gestione indici dbForge
dbForge Index Manager è un componente aggiuntivo SSMS, che serve a rilevare e risolvere i problemi di frammentazione degli indici di SQL Server.
È anche uno strumento centralizzato, che offre la possibilità di rilevare la percentuale di frammentazione dell'indice nei database. È possibile risolvere questi problemi eseguendo una ricostruzione dell'indice. Un altro modo è riorganizzare le operazioni, in base alla gravità della frammentazione di tale indice. Tra le altre opzioni, c'è la generazione di script T-SQL per l'esecuzione di comandi relativi all'indice, l'esportazione dei risultati dell'analisi dell'indice per riferimenti successivi e l'utilizzo dell'interfaccia della riga di comando per automatizzare le attività di manutenzione dell'indice.
dbForge Index Manager è disponibile nella pagina di download di Devart. Puoi installarlo sulla tua macchina usando una procedura guidata di installazione diretta. Dopo la corretta installazione, questo componente aggiuntivo è pronto per l'uso.
Per utilizzarlo all'interno dell'SSMS, fai clic con il pulsante destro del mouse sul database e scegli Gestisci frammentazione dell'indice dall'elenco Gestore indici:
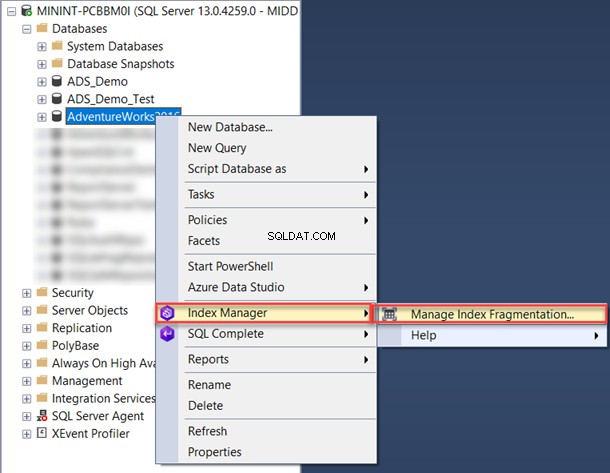
Dalla finestra Gestore indici, puoi filtrare il nome del database che ti interessa.
Fai clic su Rianalizza per eseguire il controllo della frammentazione dell'indice per il database selezionato. Mostra automaticamente le statistiche sulla frammentazione dell'indice per tutti gli indici creati nel database selezionato durante questo processo.
Lo strumento Index Manager consiglia inoltre le azioni per risolvere i problemi di frammentazione dell'indice, in base alla percentuale di frammentazione:
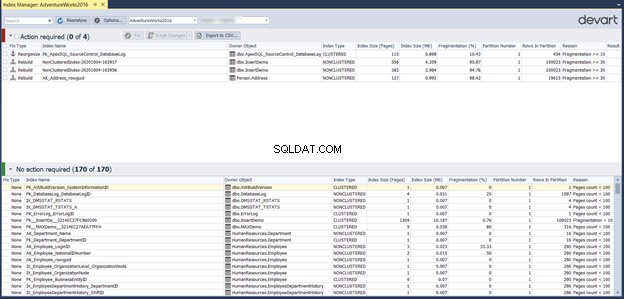
Il controllo degli indici nella sezione Azioni richieste nella finestra precedente consente di esportare l'elenco delle azioni come report CSV. Ti consente di eseguire la correzione suggerita riorganizzando o ricostruendo gli indici problematici direttamente da quella pagina o generando uno script per farlo in un secondo momento:
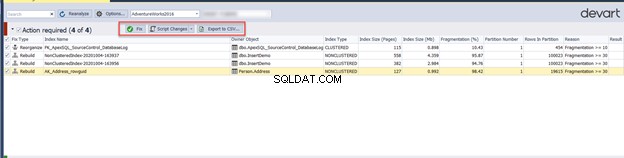
La correzione della frammentazione dell'indice nel nostro scenario sarà la seguente:
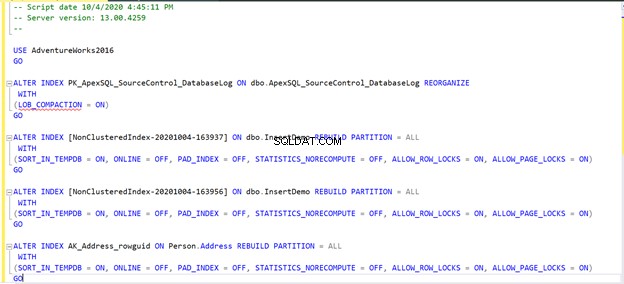
Se esegui lo script precedente o fai clic su Correggi opzione, quindi Rianalizza il risultato, vedrai che il problema di frammentazione è stato risolto direttamente:
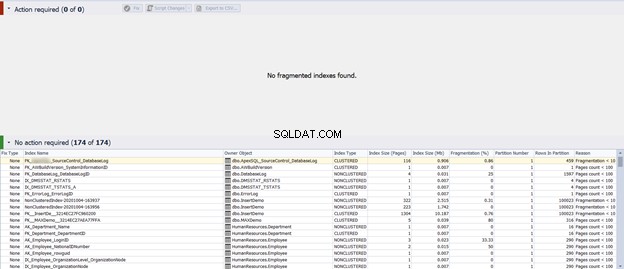
In questo modo, sfruttiamo il dbForge Index Manager per analizzare e identificare i problemi di frammentazione dell'indice e quindi segnalarli o risolverli direttamente dalla stessa posizione.
Strumento utile
dbForge Index Manager porta la correzione intelligente dell'indice e la frammentazione dell'indice direttamente in SSMS. Lo strumento consente di raccogliere rapidamente statistiche sulla frammentazione dell'indice e rilevare i database che richiedono manutenzione. Puoi ricostruire e riorganizzare istantaneamente gli indici di SQL Server in modalità visiva o generare script SQL per un uso futuro. dbForge Index Manager per SQL Server aumenterà notevolmente le tue prestazioni senza troppi sforzi.