shared hit essenzialmente significa che il valore è già stato memorizzato nella cache nella memoria principale del computer e non è stato necessario leggerlo dal disco rigido.
L'accesso alla memoria principale (RAM) è molto più veloce della lettura dei valori dal disco rigido. Ed è per questo che la query è più veloce quanto più hit di condivisione ha.
Subito dopo l'avvio di Postgres, nessuno dei dati è disponibile nella memoria principale (RAM) e tutto deve essere letto dall'hard disk.
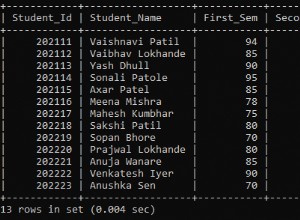
Considera questo passaggio da un piano di esecuzione:
-> Seq Scan on products.product_price (cost=0.00..3210.27 rows=392273 width=0) (actual time=0.053..103.958 rows=392273 loops=1)
Output: product_id, valid_from, valid_to, price
Buffers: shared read=2818
I/O Timings: read=48.382
La parte "Buffers:shared read=2818" significa che 2818 blocchi (ogni 8k) dovevano essere letti dal disco rigido (e ci sono voluti 48ms - ho un SSD). Quei 2818 blocchi sono stati archiviati nella cache (il "buffer condivisi ") in modo che la prossima volta che saranno necessari il database non avrà bisogno di leggerli (di nuovo) dal disco rigido (lento).
Quando eseguo nuovamente quella dichiarazione, il piano cambia in:
-> Seq Scan on products.product_price (cost=0.00..3210.27 rows=392273 width=0) (actual time=0.012..45.690 rows=392273 loops=1)
Output: product_id, valid_from, valid_to, price
Buffers: shared hit=2818
Ciò significa che quei 2818 blocchi che l'istruzione precedente erano ancora nella memoria principale (=RAM) e Postgres non aveva bisogno di leggerli dal disco rigido.
"memoria" si riferisce sempre alla memoria principale (RAM) incorporata nel computer e direttamente accessibile alla CPU, al contrario di "archiviazione esterna".
Ci sono diverse presentazioni su come Postgres gestisce i buffer condivisi:
- https://de.slideshare.net/EnterpriseDB/insidepostgressharedmemory2015
- https://momjian.us/main/writings/pgsql/hw_performance/
- https://2ndquadrant.com/media/pdfs/talks/InsideBufferCache. pdf (molto tecnico)
- https://raghavt.blogspot.de/2012/ 04/caching-in-postgresql.html