La seguente estensione del codice del test è informativa:
CREATE OR REPLACE FUNCTION test_multi_calls1(one integer)
RETURNS integer
AS $BODY$
BEGIN
RAISE NOTICE 'Immutable called with %', one;
RETURN one;
END;
$BODY$ LANGUAGE plpgsql IMMUTABLE;
CREATE OR REPLACE FUNCTION test_multi_calls2(one integer)
RETURNS integer
AS $BODY$
BEGIN
RAISE NOTICE 'Volatile called with %', one;
RETURN one;
END;
$BODY$ LANGUAGE plpgsql VOLATILE;
WITH data AS
(
SELECT 10 AS num
UNION ALL SELECT 10
UNION ALL SELECT 20
)
SELECT test_multi_calls1(num)
FROM data
where test_multi_calls2(40) = 40
and test_multi_calls1(30) = 30
USCITA:
NOTICE: Immutable called with 30
NOTICE: Volatile called with 40
NOTICE: Immutable called with 10
NOTICE: Volatile called with 40
NOTICE: Immutable called with 10
NOTICE: Volatile called with 40
NOTICE: Immutable called with 20
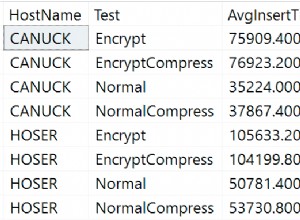
Qui possiamo vedere che mentre nella select-list la funzione immutabile è stata chiamata più volte, nella clausola where è stata chiamata una volta, mentre la volatile è stata chiamata tre volte.
La cosa importante non è che PostgreSQL chiamerà solo una STABLE o IMMUTABLE funzione una volta con gli stessi dati - il tuo esempio mostra chiaramente che non è così - è che potrebbe chiamalo solo una volta. O forse lo chiamerà due volte quando dovrebbe chiamare una versione volatile 50 volte e così via.
Esistono diversi modi in cui è possibile sfruttare stabilità e immutabilità, con costi e benefici diversi. Per fornire il tipo di salvataggio che stai suggerendo che dovrebbe fare con le liste di selezione, dovrebbe memorizzare nella cache i risultati e quindi cercare ogni argomento (o elenco di argomenti) in questa cache prima di restituire il risultato memorizzato nella cache o di chiamare la funzione su una cache -Perdere. Questo sarebbe più costoso che chiamare la tua funzione, anche nel caso in cui ci fosse un'alta percentuale di hit della cache (potrebbero esserci hit della cache dello 0%, il che significa che questa "ottimizzazione" ha fatto un lavoro extra senza alcun guadagno). Potrebbe memorizzare forse solo l'ultimo parametro e risultato, ma anche in questo caso potrebbe essere completamente inutile.
Ciò è particolarmente vero considerando che le funzioni stabili e immutabili sono spesso le funzioni più leggere.
Con la clausola where invece, l'immutabilità di test_multi_calls1 consente a PostgreSQL di ristrutturare effettivamente la query dal semplice significato dell'SQL dato:
A un piano di query completamente diverso:
Questo è il tipo di utilizzo che PostgreSQL fa di STABILE e IMMUTABLE:non la memorizzazione nella cache dei risultati, ma la riscrittura di query in query diverse che sono più efficienti ma danno gli stessi risultati.
Nota anche che test_multi_calls1(30) viene chiamato prima di test_multi_calls2(40) indipendentemente dall'ordine in cui appaiono nella clausola where. Ciò significa che se la prima chiamata non restituisce righe (sostituisci = 30 con = 31 da testare) quindi la funzione volatile non verrà affatto chiamata, di nuovo indipendentemente da quale lato del and .
Questo particolare tipo di riscrittura dipende dall'immutabilità o dalla stabilità. Con where test_multi_calls1(30) != num la riscrittura della query avverrà per funzioni immutabili ma non semplicemente stabili. Con where test_multi_calls1(num) != 30 non accadrà affatto (chiamate multiple) anche se sono possibili altre ottimizzazioni:
Le espressioni contenenti solo funzioni STABILE e IMMUTABLE possono essere utilizzate con le scansioni dell'indice. Le espressioni contenenti funzioni VOLATILE non possono. Il numero di chiamate può diminuire o meno, ma ancora più importante i risultati delle chiamate verranno quindi utilizzati in un modo molto più efficiente nel resto della query (importa davvero solo su tabelle di grandi dimensioni, ma può fare un enorme differenza).
In definitiva, non pensare alle categorie di volatilità in termini di memorizzazione, ma piuttosto in termini di opportunità per il pianificatore di query di PostgreSQL di ristrutturare intere query in modi logicamente equivalenti (stessi risultati) ma molto più efficienti.