Non esiste un sistema, un hardware o una topologia perfetti per evitare tutti i possibili problemi che potrebbero verificarsi in un ambiente di produzione. Il superamento di queste sfide richiede un efficace DRP (Disaster Recovery Plan), configurato in base alla tua applicazione, infrastruttura e requisiti aziendali. La chiave del successo in questo tipo di situazioni è sempre la velocità con cui possiamo risolvere o risolvere il problema.
In questo blog daremo un'occhiata agli scenari di errore di PostgreSQL più comuni e ti mostreremo come puoi risolvere o far fronte ai problemi. Vedremo anche come ClusterControl può aiutarci a tornare online
La topologia comune di PostgreSQL
Per comprendere gli scenari di errore comuni, devi prima iniziare con una topologia PostgreSQL comune. Può essere qualsiasi applicazione connessa a un nodo primario PostgreSQL a cui è collegata una replica.
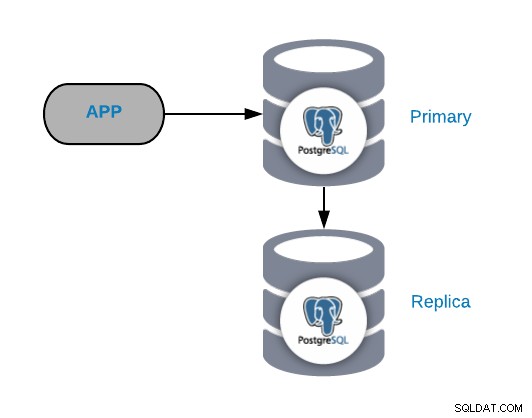
Puoi sempre migliorare o espandere questa topologia aggiungendo più nodi o bilanciatori di carico , ma questa è la topologia di base con cui inizieremo a lavorare.
Errore del nodo PostgreSQL primario
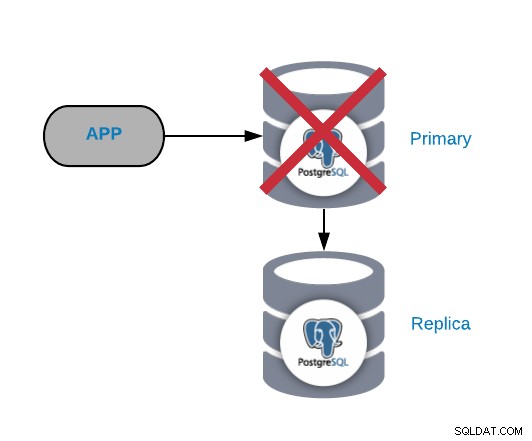
Questo è uno degli errori più critici in quanto dovremmo risolverlo al più presto se vogliamo mantenere i nostri sistemi online. Per questo tipo di errore è importante disporre di una sorta di meccanismo di failover automatico. Dopo il fallimento, puoi esaminare il motivo dei problemi. Dopo il processo di failover, ci assicuriamo che il nodo primario guasto non pensi ancora di essere il nodo primario. Questo per evitare l'incoerenza dei dati durante la scrittura.
Le cause più comuni di questo tipo di problema sono un errore del sistema operativo, un errore dell'hardware o un errore del disco. In ogni caso, dovremmo controllare il database e i log del sistema operativo per trovare il motivo.
La soluzione più rapida per questo problema è eseguire un'attività di failover per ridurre i tempi di inattività Per promuovere una replica possiamo usare il comando pg_ctl promote sul nodo del database slave, quindi dobbiamo inviare il traffico dal applicazione al nuovo nodo primario. Per quest'ultima attività, possiamo implementare un bilanciamento del carico tra la nostra applicazione e i nodi del database, per evitare qualsiasi modifica dal lato dell'applicazione in caso di guasto. Possiamo anche configurare il sistema di bilanciamento del carico per rilevare l'errore del nodo e invece di inviargli traffico, invii il traffico al nuovo nodo primario.
Dopo il processo di failover e assicurandoci che il sistema funzioni di nuovo, possiamo esaminare il problema e consigliamo di mantenere sempre funzionante almeno un nodo slave, quindi in caso di un nuovo errore primario, possiamo eseguire nuovamente l'attività di failover.
Errore del nodo di replica PostgreSQL
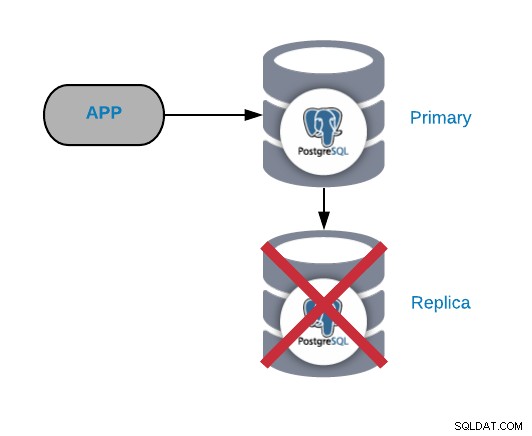
Questo non è normalmente un problema critico (purché tu abbia più di una replica e non la stanno utilizzando per inviare il traffico di produzione in lettura). Se riscontri problemi sul nodo principale e non hai la tua replica aggiornata, avrai un vero problema critico. Se stai utilizzando la nostra replica per scopi di report o big data, probabilmente vorrai comunque risolverlo rapidamente.
Le cause più comuni di questo tipo di problema sono le stesse che abbiamo riscontrato per il nodo primario, un errore del sistema operativo, un errore hardware o un errore del disco. Dovresti controllare il database e i log del sistema operativo per trovare il motivo.
Non è consigliabile mantenere il sistema in funzione senza alcuna replica poiché, in caso di guasto, non si dispone di un modo rapido per tornare online. Se hai un solo slave, dovresti risolvere il problema il prima possibile; il modo più veloce è creare una nuova replica da zero. Per questo dovrai eseguire un backup coerente e ripristinarlo sul nodo slave, quindi configurare la replica tra questo nodo slave e il nodo primario.
Se desideri conoscere il motivo dell'errore, dovresti utilizzare un altro server per creare la nuova replica, quindi esaminare quella vecchia per scoprirla. Al termine di questa attività, puoi anche riconfigurare la vecchia replica e continuare a funzionare entrambe come futura opzione di failover.
Se stai utilizzando la replica per la creazione di report o per big data, devi modificare l'indirizzo IP per connetterti a quello nuovo. Come nel caso precedente, un modo per evitare questa modifica è utilizzare un sistema di bilanciamento del carico che conoscerà lo stato di ciascun server, consentendoti di aggiungere/rimuovere repliche come desideri.
Errore di replica PostgreSQL
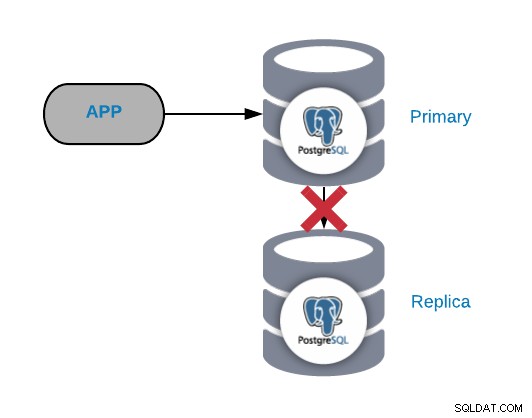
In generale, questo tipo di problema viene generato a causa di una rete o di una configurazione problema. È correlato a una perdita WAL (Write-Ahead Logging) nel nodo primario e al modo in cui PostgreSQL gestisce la replica.
Se hai traffico importante, stai facendo checkpoint troppo frequentemente o stai archiviando WALS solo per pochi minuti; se hai un problema di rete avrai poco tempo per risolverlo. I tuoi WAL verrebbero eliminati prima che tu possa inviarli e applicarli alla replica.
Se il WAL di cui la replica ha bisogno per continuare a funzionare è stato eliminato è necessario ricostruirlo, quindi per evitare questa attività, dovremmo controllare la configurazione del nostro database per aumentare i wal_keep_segments (quantità di WALS da mantenere nel pg_xlog) o i parametri max_wal_senders (numero massimo di processi mittente WAL in esecuzione simultanea).
Un'altra opzione consigliata è configurare archive_mode e inviare i file WAL a un altro percorso con il parametro archive_command. In questo modo, se PostgreSQL raggiunge il limite ed elimina il file WAL, lo avremo comunque in un altro percorso.
Corruzione dei dati PostgreSQL/Incoerenza dei dati/Cancellazione accidentale

Questo è un incubo per qualsiasi DBA e probabilmente il problema più complesso da affrontare risolto, a seconda della diffusione del problema.
Quando i tuoi dati sono interessati da alcuni di questi problemi, il modo più comune per risolverli (e probabilmente l'unico) è ripristinare un backup. Ecco perché i backup sono la forma base di qualsiasi piano di ripristino di emergenza e si consiglia di avere almeno tre backup archiviati in luoghi fisici diversi. La best practice impone che i file di backup ne abbiano uno archiviato localmente sul server del database (per un ripristino più rapido), un altro in un server di backup centralizzato e l'ultimo sul cloud.
Possiamo anche creare un mix di backup compatibili PITR completi/incrementali/differenziali per ridurre il nostro obiettivo del punto di ripristino.
Gestione degli errori di PostgreSQL con ClusterControl
Ora che abbiamo esaminato questi comuni scenari di errore di PostgreSQL, diamo un'occhiata a cosa accadrebbe se gestissimo i database PostgreSQL da un sistema di gestione database centralizzato. Uno che è ottimo in termini di raggiungere un modo semplice e veloce per risolvere il problema, il prima possibile, in caso di errore.
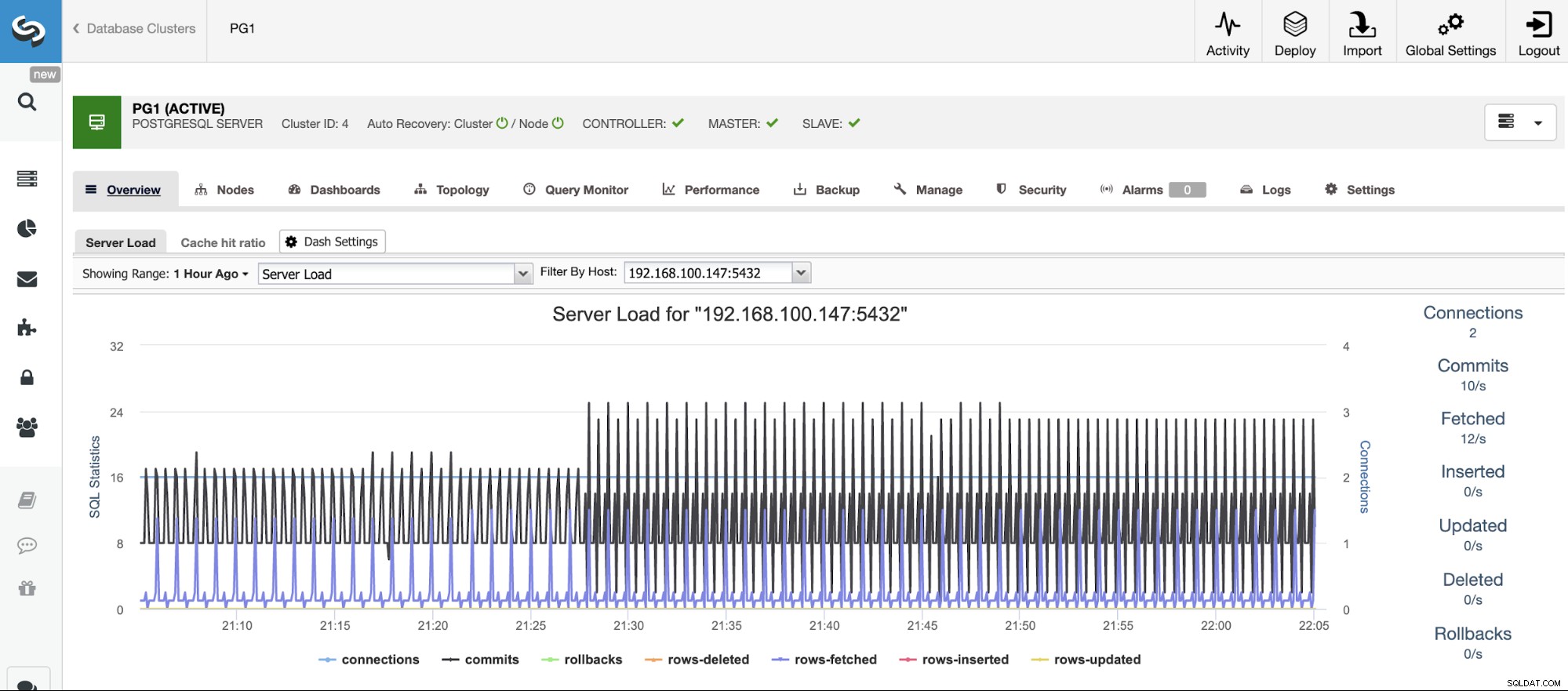
ClusterControl fornisce l'automazione per la maggior parte delle attività PostgreSQL descritte sopra; il tutto in modo centralizzato e intuitivo. Con questo sistema sarai in grado di configurare facilmente cose che, manualmente, richiederebbero tempo e fatica. Esamineremo ora alcune delle sue principali caratteristiche relative agli scenari di errore di PostgreSQL.
Distribuisci/importa un cluster PostgreSQL
Una volta entrati nell'interfaccia ClusterControl, la prima cosa da fare è distribuire un nuovo cluster o importarne uno esistente. Per eseguire una distribuzione, seleziona semplicemente l'opzione Distribuisci cluster di database e segui le istruzioni visualizzate.
Ridimensionamento del cluster PostgreSQL
Se vai su Cluster Actions e selezioni Aggiungi replica slave, puoi creare una nuova replica da zero o aggiungere un database PostgreSQL esistente come replica. In questo modo, puoi far funzionare la tua nuova replica in pochi minuti e possiamo aggiungere tutte le repliche che vogliamo; distribuendo tra loro il traffico di lettura utilizzando un sistema di bilanciamento del carico (che possiamo implementare anche con ClusterControl).
Failover automatico di PostgreSQL
ClusterControl gestisce il failover sulla configurazione della replica. Rileva i guasti del master e promuove uno slave con i dati più aggiornati come nuovo master. Inoltre, esegue automaticamente il failover del resto degli slave per la replica dal nuovo master. Per quanto riguarda le connessioni client, sfrutta due strumenti per l'attività:HAProxy e Keepalived.
HAProxy è un sistema di bilanciamento del carico che distribuisce il traffico da un'origine a una o più destinazioni e può definire regole e/o protocolli specifici per l'attività. Se una delle destinazioni smette di rispondere, viene contrassegnata come offline e il traffico viene inviato a una delle destinazioni disponibili. Ciò impedisce che il traffico venga inviato a una destinazione inaccessibile e la perdita di queste informazioni indirizzandolo a una destinazione valida.
Keepalived consente di configurare un IP virtuale all'interno di un gruppo di server attivo/passivo. Questo IP virtuale è assegnato a un server "Principale" attivo. Se questo server si guasta, l'IP viene automaticamente migrato al server "Secondario" ritenuto passivo, consentendogli di continuare a lavorare con lo stesso IP in modo trasparente per i nostri sistemi.
Aggiunta di un sistema di bilanciamento del carico PostgreSQL
Se vai su Cluster Actions e seleziona Aggiungi Load Balancer (o dalla vista cluster - vai su Manage -> Load Balancer) puoi aggiungere load balancer alla nostra topologia di database.
La configurazione necessaria per creare il tuo nuovo sistema di bilanciamento del carico è abbastanza semplice. Devi solo aggiungere IP/Hostname, porta, policy e i nodi che useremo. Puoi aggiungere due sistemi di bilanciamento del carico con Keepalived tra di loro, che ci consente di avere un failover automatico del nostro sistema di bilanciamento del carico in caso di errore. Keepalived utilizza un indirizzo IP virtuale e lo migra da un sistema di bilanciamento del carico a un altro in caso di errore, in modo che la nostra configurazione possa continuare a funzionare normalmente.
Backup PostgreSQL
Abbiamo già discusso dell'importanza di disporre di backup. ClusterControl fornisce la funzionalità per generare un backup immediato o pianificarne uno.
Puoi scegliere tra tre diversi metodi di backup, pgdump, pg_basebackup o pgBackRest. Puoi anche specificare dove archiviare i backup (sul server del database, sul server ClusterControl o nel cloud), il livello di compressione, la crittografia richiesta e il periodo di conservazione.
Monitoraggio e avvisi PostgreSQL
Prima di poter agire, devi sapere cosa sta succedendo, quindi dovrai monitorare il tuo cluster di database. ClusterControl ti consente di monitorare i nostri server in tempo reale. Sono disponibili grafici con dati di base come CPU, rete, disco, RAM, IOPS, nonché metriche specifiche del database raccolte dalle istanze PostgreSQL. Le query del database possono essere visualizzate anche da Query Monitor.
Allo stesso modo in cui abiliti il monitoraggio da ClusterControl, puoi anche impostare avvisi che ti informano sugli eventi nel tuo cluster. Questi avvisi sono configurabili e possono essere personalizzati in base alle esigenze.
Conclusione
Tutti alla fine dovranno far fronte a problemi e guasti di PostgreSQL. E poiché non puoi evitare il problema, devi essere in grado di risolverlo il prima possibile e mantenere il sistema in esecuzione. Abbiamo anche visto come l'utilizzo di ClusterControl può aiutare con questi problemi; il tutto da un'unica piattaforma user-friendly.
Questi sono quelli che pensavamo fossero alcuni degli scenari di errore più comuni per PostgreSQL. Ci piacerebbe conoscere le tue esperienze e come l'hai risolto.