Storicamente, il compito più difficile quando si lavora con PostgreSQL è stato gestire gli aggiornamenti. Il modo più intuitivo di aggiornamento che puoi pensare è generare una replica in una nuova versione ed eseguire un failover dell'applicazione in essa. Con PostgreSQL, questo semplicemente non era possibile in modo nativo. Per eseguire gli aggiornamenti dovevi pensare ad altri modi di aggiornare, come l'utilizzo di pg_upgrade, il dumping e il ripristino o l'utilizzo di alcuni strumenti di terze parti come Slony o Bucardo, tutti con le proprie avvertenze.
Perché era questo? A causa del modo in cui PostgreSQL implementa la replica.
La replica in streaming integrata di PostgreSQL è ciò che viene chiamato fisico:replicherà le modifiche a livello di byte per byte, creando una copia identica del database in un altro server. Questo metodo ha molte limitazioni quando si pensa a un aggiornamento, poiché semplicemente non è possibile creare una replica in una versione del server diversa o anche in un'architettura diversa.
Quindi, qui è dove PostgreSQL 10 diventa un punto di svolta. Con queste nuove versioni 10 e 11, PostgreSQL implementa la replica logica incorporata che, a differenza della replica fisica, è possibile replicare tra diverse versioni principali di PostgreSQL. Questo, ovviamente, apre una nuova porta per l'aggiornamento delle strategie.
In questo blog, vediamo come possiamo aggiornare il nostro PostgreSQL 10 a PostgreSQL 11 senza tempi di inattività utilizzando la replica logica. Prima di tutto, esaminiamo un'introduzione alla replica logica.
Cos'è la replica logica?
La replica logica è un metodo per replicare gli oggetti dati e le relative modifiche, in base alla loro identità di replica (di solito una chiave primaria). Si basa su una modalità di pubblicazione e sottoscrizione, in cui uno o più abbonati si iscrivono a una o più pubblicazioni su un nodo editore.
Una pubblicazione è un insieme di modifiche generate da una tabella o da un gruppo di tabelle (denominato anche set di replica). Il nodo in cui è definita una pubblicazione è denominato editore. Una sottoscrizione è il lato a valle della replica logica. Il nodo in cui è definita una sottoscrizione è denominato abbonato e definisce la connessione a un altro database e insieme di pubblicazioni (una o più) a cui desidera iscriversi. Gli abbonati estraggono i dati dalle pubblicazioni a cui si iscrivono.
La replica logica è realizzata con un'architettura simile alla replica dello streaming fisico. È implementato dai processi "walsender" e "applica". Il processo walsender avvia la decodifica logica del WAL e carica il plug-in di decodifica logica standard. Il plugin trasforma le modifiche lette da WAL nel protocollo di replica logica e filtra i dati in base alle specifiche di pubblicazione. I dati vengono quindi trasferiti continuamente utilizzando il protocollo di replica in streaming al lavoratore applicato, che mappa i dati su tabelle locali e applica le singole modifiche man mano che vengono ricevute, in un corretto ordine transazionale.
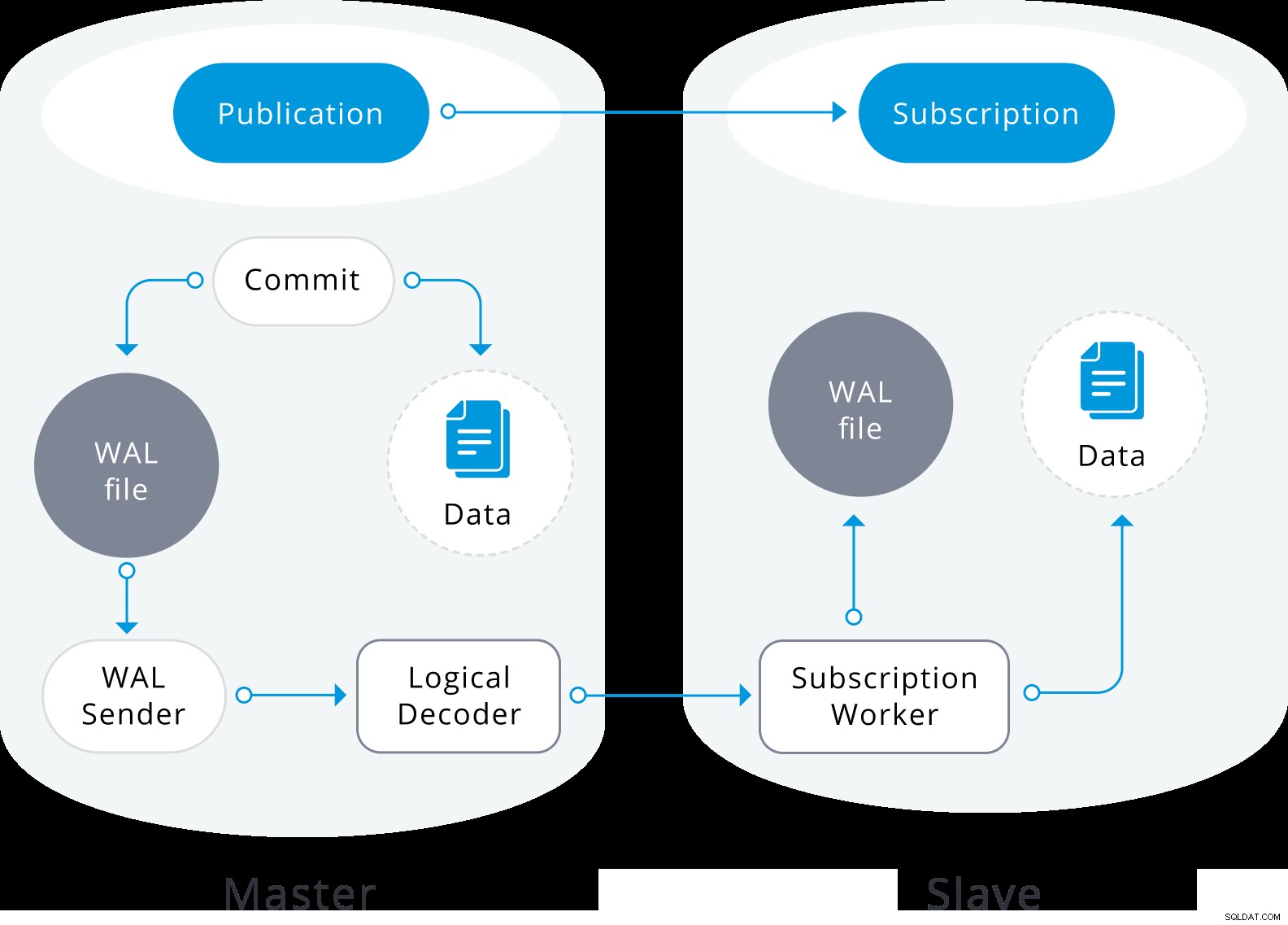 Diagramma di replica logica
Diagramma di replica logica La replica logica inizia acquisendo uno snapshot dei dati nel database dell'editore e copiandolo nel sottoscrittore. I dati iniziali nelle tabelle sottoscritte esistenti vengono catturati e copiati in un'istanza parallela di un tipo speciale di processo di applicazione. Questo processo creerà il proprio slot di replica temporaneo e copierà i dati esistenti. Una volta copiati i dati esistenti, il lavoratore entra in modalità di sincronizzazione, che assicura che la tabella venga portata a uno stato sincronizzato con il processo di applicazione principale trasmettendo in streaming tutte le modifiche avvenute durante la copia dei dati iniziale utilizzando la replica logica standard. Una volta eseguita la sincronizzazione, il controllo della replica della tabella viene restituito al processo di applicazione principale in cui la replica continua normalmente. Le modifiche sull'editore vengono inviate all'abbonato man mano che si verificano in tempo reale.
Puoi trovare ulteriori informazioni sulla replica logica nei seguenti blog:
- Una panoramica della replica logica in PostgreSQL
- Replica in streaming PostgreSQL e replica logica
Come aggiornare PostgreSQL 10 a PostgreSQL 11 utilizzando la replica logica
Quindi, ora che sappiamo di cosa tratta questa nuova funzionalità, possiamo pensare a come utilizzarla per risolvere il problema dell'aggiornamento.
Configurare la replica logica tra due diverse versioni principali di PostgreSQL (10 e 11) e, naturalmente, dopo aver funzionato, si tratta solo di eseguire un failover dell'applicazione nel database con la versione più recente.
Eseguiremo i seguenti passaggi per far funzionare la replica logica:
- Configura il nodo editore
- Configura il nodo abbonato
- Crea l'utente abbonato
- Crea una pubblicazione
- Crea la struttura della tabella nell'iscritto
- Crea l'abbonamento
- Verifica lo stato della replica
Allora iniziamo.
Sul lato editore, configureremo i seguenti parametri nel file postgresql.conf:
- listen_addresses:su quali indirizzi IP ascoltare. Useremo '*' per tutti.
- wal_level:determina quante informazioni vengono scritte nel WAL. Lo imposteremo su logico.
- max_replication_slots:specifica il numero massimo di slot di replica che il server può supportare. Deve essere impostato almeno sul numero di abbonamenti previsti per la connessione, più una riserva per la sincronizzazione delle tabelle.
- max_wal_senders:specifica il numero massimo di connessioni simultanee da server in standby o client di backup di base in streaming. Dovrebbe essere almeno uguale a max_replication_slots più il numero di repliche fisiche connesse contemporaneamente.
Tieni presente che alcuni di questi parametri richiedono il riavvio del servizio PostgreSQL per essere applicati.
Anche il file pg_hba.conf deve essere modificato per consentire la replica. È necessario consentire all'utente di replica di connettersi al database.
Quindi, sulla base di questo, configuriamo il nostro editore (in questo caso il nostro server PostgreSQL 10) come segue:
- postgresql.conf:
listen_addresses = '*' wal_level = logical max_wal_senders = 8 max_replication_slots = 4 - pg_hba.conf:
# TYPE DATABASE USER ADDRESS METHOD host all rep 192.168.100.144/32 md5
Dobbiamo cambiare l'utente (nel nostro rappresentante di esempio), che verrà utilizzato per la replica, e l'indirizzo IP 192.168.100.144/32 per l'IP che corrisponde al nostro PostgreSQL 11.
Sul lato abbonato, richiede anche l'impostazione di max_replication_slots. In questo caso, dovrebbe essere impostato almeno sul numero di abbonamenti che verranno aggiunti all'abbonato.
Anche gli altri parametri che devono essere impostati qui sono:
- max_logical_replication_workers:specifica il numero massimo di worker di replica logica. Ciò include sia i ruoli di lavoro applicati che quelli di sincronizzazione delle tabelle. I lavoratori di replica logica vengono presi dal pool definito da max_worker_processes. Deve essere impostato almeno al numero di iscrizioni, sempre più una riserva per la sincronizzazione delle tabelle.
- max_worker_processes:imposta il numero massimo di processi in background che il sistema può supportare. Potrebbe essere necessario adattarlo per adattarsi ai lavoratori di replica, almeno max_logical_replication_workers + 1. Questo parametro richiede un riavvio di PostgreSQL.
Quindi, dobbiamo configurare il nostro abbonato (in questo caso il nostro server PostgreSQL 11) come segue:
- postgresql.conf:
listen_addresses = '*' max_replication_slots = 4 max_logical_replication_workers = 4 max_worker_processes = 8
Poiché questo PostgreSQL 11 sarà presto il nostro nuovo master, dovremmo considerare di aggiungere i parametri wal_level e archive_mode in questo passaggio, per evitare un nuovo riavvio del servizio in seguito.
wal_level = logical
archive_mode = onQuesti parametri saranno utili se vogliamo aggiungere un nuovo slave di replica o per utilizzare i backup PITR.
Nell'editore, dobbiamo creare l'utente con cui si collegherà il nostro abbonato:
world=# CREATE ROLE rep WITH LOGIN PASSWORD '*****' REPLICATION;
CREATE ROLEIl ruolo utilizzato per la connessione di replica deve avere l'attributo REPLICATION. L'accesso per il ruolo deve essere configurato in pg_hba.conf e deve avere l'attributo LOGIN.
Per poter copiare i dati iniziali, il ruolo utilizzato per la connessione di replica deve disporre del privilegio SELECT su una tabella pubblicata.
world=# GRANT SELECT ON ALL TABLES IN SCHEMA public to rep;
GRANTCreeremo la pubblicazione pub1 nel nodo editore, per tutte le tabelle:
world=# CREATE PUBLICATION pub1 FOR ALL TABLES;
CREATE PUBLICATIONL'utente che creerà una pubblicazione deve disporre del privilegio CREATE nel database, ma per creare una pubblicazione che pubblichi tutte le tabelle automaticamente, l'utente deve essere un superutente.
Per confermare la pubblicazione creata utilizzeremo il catalogo pg_publication. Questo catalogo contiene informazioni su tutte le pubblicazioni create nel database.
world=# SELECT * FROM pg_publication;
-[ RECORD 1 ]+------
pubname | pub1
pubowner | 16384
puballtables | t
pubinsert | t
pubupdate | t
pubdelete | tDescrizioni delle colonne:
- pubname:nome della pubblicazione.
- pubowner:proprietario della pubblicazione.
- puballtables:se true, questa pubblicazione include automaticamente tutte le tabelle nel database, comprese quelle che verranno create in futuro.
- pubinsert:se true, le operazioni INSERT vengono replicate per le tabelle nella pubblicazione.
- pubupdate:se true, le operazioni UPDATE vengono replicate per le tabelle nella pubblicazione.
- pubdelete:se true, le operazioni DELETE vengono replicate per le tabelle nella pubblicazione.
Poiché lo schema non viene replicato, dobbiamo eseguire un backup in PostgreSQL 10 e ripristinarlo nel nostro PostgreSQL 11. Il backup verrà eseguito solo per lo schema, poiché le informazioni verranno replicate nel trasferimento iniziale.
In PostgreSQL 10:
$ pg_dumpall -s > schema.sqlIn PostgreSQL 11:
$ psql -d postgres -f schema.sqlUna volta che abbiamo il nostro schema in PostgreSQL 11, creiamo la sottoscrizione, sostituendo i valori di host, dbname, user e password con quelli che corrispondono al nostro ambiente.
PostgreSQL 11:
world=# CREATE SUBSCRIPTION sub1 CONNECTION 'host=192.168.100.143 dbname=world user=rep password=*****' PUBLICATION pub1;
NOTICE: created replication slot "sub1" on publisher
CREATE SUBSCRIPTIONQuanto sopra avvierà il processo di replica, che sincronizza il contenuto della tabella iniziale delle tabelle nella pubblicazione e quindi avvia la replica delle modifiche incrementali a tali tabelle.
L'utente che crea un abbonamento deve essere un superutente. Il processo di richiesta dell'abbonamento verrà eseguito nel database locale con i privilegi di un superutente.
Per verificare l'abbonamento creato possiamo utilizzare quindi il catalogo pg_stat_subscription. Questa visualizzazione conterrà una riga per sottoscrizione per il lavoratore principale (con PID nullo se il lavoratore non è in esecuzione) e righe aggiuntive per i lavoratori che gestiscono la copia dei dati iniziale delle tabelle sottoscritte.
world=# SELECT * FROM pg_stat_subscription;
-[ RECORD 1 ]---------+------------------------------
subid | 16428
subname | sub1
pid | 1111
relid |
received_lsn | 0/172AF90
last_msg_send_time | 2018-12-05 22:11:45.195963+00
last_msg_receipt_time | 2018-12-05 22:11:45.196065+00
latest_end_lsn | 0/172AF90
latest_end_time | 2018-12-05 22:11:45.195963+00Descrizioni delle colonne:
- subid:OID dell'abbonamento.
- sottonome:nome dell'abbonamento.
- pid:ID processo del processo di lavoro di sottoscrizione.
- relid:OID della relazione che il lavoratore sta sincronizzando; nullo per il lavoratore principale candidato.
- received_lsn:ultima posizione del registro write-ahead ricevuta, il valore iniziale di questo campo è 0.
- last_msg_send_time:invia l'ora dell'ultimo messaggio ricevuto dal mittente WAL di origine.
- last_msg_receipt_time:ora di ricezione dell'ultimo messaggio ricevuto dal mittente WAL di origine.
- latest_end_lsn:ultima posizione del registro write-ahead segnalata al mittente WAL di origine.
- latest_end_time:ora dell'ultima posizione del registro write-ahead segnalata al mittente WAL di origine.
Per verificare lo stato della replica nel master possiamo usare pg_stat_replication:
world=# SELECT * FROM pg_stat_replication;
-[ RECORD 1 ]----+------------------------------
pid | 1178
usesysid | 16427
usename | rep
application_name | sub1
client_addr | 192.168.100.144
client_hostname |
client_port | 58270
backend_start | 2018-12-05 22:11:45.097539+00
backend_xmin |
state | streaming
sent_lsn | 0/172AF90
write_lsn | 0/172AF90
flush_lsn | 0/172AF90
replay_lsn | 0/172AF90
write_lag |
flush_lag |
replay_lag |
sync_priority | 0
sync_state | asyncDescrizioni delle colonne:
- pid:ID processo di un processo mittente WAL.
- usesysid:OID dell'utente connesso a questo processo mittente WAL.
- usename:nome dell'utente connesso a questo processo mittente WAL.
- nome_applicazione:nome dell'applicazione collegata a questo mittente WAL.
- client_addr:indirizzo IP del client connesso a questo mittente WAL. Se questo campo è nullo, indica che il client è connesso tramite un socket Unix sulla macchina server.
- client_hostname:nome host del client connesso, come riportato da una ricerca DNS inversa di client_addr. Questo campo non sarà nullo solo per le connessioni IP e solo quando log_hostname è abilitato.
- porta_client:numero della porta TCP utilizzata dal client per la comunicazione con questo mittente WAL o -1 se viene utilizzato un socket Unix.
- backend_start:ora in cui è stato avviato questo processo.
- backend_xmin:l'orizzonte xmin di questo standby segnalato da hot_standby_feedback.
- stato:stato del mittente WAL corrente. I valori possibili sono:avvio, recupero, streaming, backup e arresto.
- sent_lsn:ultima posizione del registro write-ahead inviata su questa connessione.
- write_lsn:ultima posizione del registro write-ahead scritta su disco da questo server di standby.
- flush_lsn:ultima posizione del registro write-ahead scaricata su disco da questo server di standby.
- replay_lsn:ultima posizione del registro write-ahead riprodotta nel database su questo server di standby.
- write_lag:tempo trascorso tra lo svuotamento locale del WAL recente e la ricezione della notifica che questo server di standby lo ha scritto (ma non lo ha ancora scaricato o applicato).
- flush_lag:tempo trascorso tra lo svuotamento locale del WAL recente e la ricezione della notifica che questo server di standby lo ha scritto e scaricato (ma non ancora applicato).
- replay_lag:tempo trascorso tra lo svuotamento locale del WAL recente e la ricezione della notifica che questo server di standby lo ha scritto, scaricato e applicato.
- sync_priority:priorità di questo server di standby per essere scelto come standby sincrono in una replica sincrona basata su priorità.
- sync_state:stato sincrono di questo server di standby. I valori possibili sono async, potenziale, sincronizzazione, quorum.
Per verificare quando il trasferimento iniziale è terminato possiamo vedere il log di PostgreSQL sull'abbonato:
2018-12-05 22:11:45.096 UTC [1111] LOG: logical replication apply worker for subscription "sub1" has started
2018-12-05 22:11:45.103 UTC [1112] LOG: logical replication table synchronization worker for subscription "sub1", table "city" has started
2018-12-05 22:11:45.114 UTC [1113] LOG: logical replication table synchronization worker for subscription "sub1", table "country" has started
2018-12-05 22:11:45.156 UTC [1112] LOG: logical replication table synchronization worker for subscription "sub1", table "city" has finished
2018-12-05 22:11:45.162 UTC [1114] LOG: logical replication table synchronization worker for subscription "sub1", table "countrylanguage" has started
2018-12-05 22:11:45.168 UTC [1113] LOG: logical replication table synchronization worker for subscription "sub1", table "country" has finished
2018-12-05 22:11:45.206 UTC [1114] LOG: logical replication table synchronization worker for subscription "sub1", table "countrylanguage" has finishedO controllando la variabile srsubstate sul catalogo pg_subscription_rel. Questo catalogo contiene lo stato di ogni relazione replicata in ogni sottoscrizione.
world=# SELECT * FROM pg_subscription_rel;
-[ RECORD 1 ]---------
srsubid | 16428
srrelid | 16387
srsubstate | r
srsublsn | 0/172AF20
-[ RECORD 2 ]---------
srsubid | 16428
srrelid | 16393
srsubstate | r
srsublsn | 0/172AF58
-[ RECORD 3 ]---------
srsubid | 16428
srrelid | 16400
srsubstate | r
srsublsn | 0/172AF90Descrizioni delle colonne:
- srsubid:riferimento all'abbonamento.
- srrelid:riferimento alla relazione.
- srsubstate:codice di stato:i =inizializza, d =è in corso la copia dei dati, s =sincronizzato, r =pronto (replica normale).
- srsublsn:termina LSN per gli stati s e r.
Possiamo inserire alcuni record di test nel nostro PostgreSQL 10 e convalidare di averli nel nostro PostgreSQL 11:
PostgreSQL 10:
world=# INSERT INTO city (id,name,countrycode,district,population) VALUES (5001,'city1','USA','District1',10000);
INSERT 0 1
world=# INSERT INTO city (id,name,countrycode,district,population) VALUES (5002,'city2','ITA','District2',20000);
INSERT 0 1
world=# INSERT INTO city (id,name,countrycode,district,population) VALUES (5003,'city3','CHN','District3',30000);
INSERT 0 1PostgreSQL 11:
world=# SELECT * FROM city WHERE id>5000;
id | name | countrycode | district | population
------+-------+-------------+-----------+------------
5001 | city1 | USA | District1 | 10000
5002 | city2 | ITA | District2 | 20000
5003 | city3 | CHN | District3 | 30000
(3 rows)A questo punto, abbiamo tutto pronto per indirizzare la nostra applicazione al nostro PostgreSQL 11.
Per questo, prima di tutto, dobbiamo confermare che non abbiamo lag di replica.
Sul maestro:
world=# SELECT application_name, pg_wal_lsn_diff(pg_current_wal_lsn(), replay_lsn) lag FROM pg_stat_replication;
-[ RECORD 1 ]----+-----
application_name | sub1
lag | 0E ora, dobbiamo solo cambiare il nostro endpoint dalla nostra applicazione o dal sistema di bilanciamento del carico (se ne abbiamo uno) al nuovo server PostgreSQL 11.
Se abbiamo un sistema di bilanciamento del carico come HAProxy, possiamo configurarlo utilizzando PostgreSQL 10 come attivo e PostgreSQL 11 come backup, in questo modo:
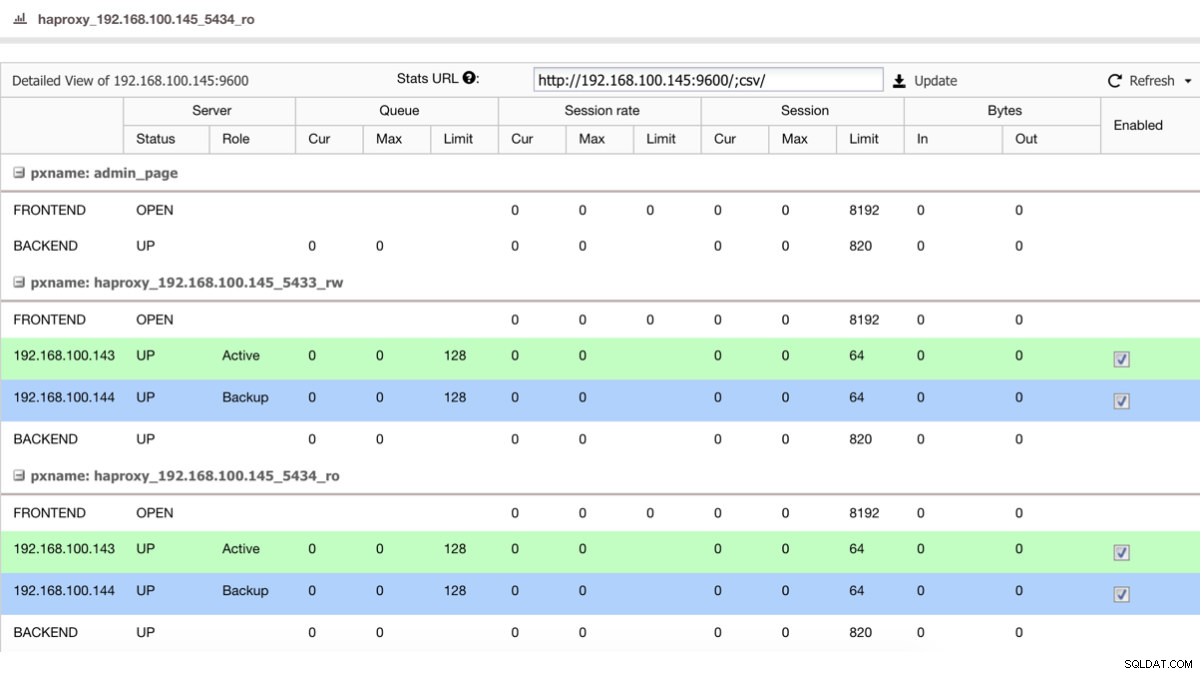 HAProxy Status View
HAProxy Status View Quindi, se hai appena spento il master in PostgreSQL 10, il server di backup, in questo caso in PostgreSQL 11, inizia a ricevere il traffico in modo trasparente per l'utente/applicazione.
Al termine della migrazione, possiamo eliminare l'abbonamento nel nostro nuovo master in PostgreSQL 11:
world=# DROP SUBSCRIPTION sub1;
NOTICE: dropped replication slot "sub1" on publisher
DROP SUBSCRIPTIONE verifica che sia stato rimosso correttamente:
world=# SELECT * FROM pg_subscription_rel;
(0 rows)
world=# SELECT * FROM pg_stat_subscription;
(0 rows)Limiti
Prima di utilizzare la replica logica, tieni presente le seguenti limitazioni:
- Lo schema del database ei comandi DDL non vengono replicati. Lo schema iniziale può essere copiato usando pg_dump --schema-only.
- I dati della sequenza non vengono replicati. I dati nelle colonne seriali o di identità supportate da sequenze verranno replicati come parte della tabella, ma la sequenza stessa mostrerebbe comunque il valore iniziale sull'abbonato.
- La replica dei comandi TRUNCATE è supportata, ma occorre prestare attenzione quando si troncano gruppi di tabelle collegate da chiavi esterne. Quando si replica un'azione di troncamento, il sottoscrittore troncherà lo stesso gruppo di tabelle che è stato troncato nell'editore, specificato in modo esplicito o raccolto implicitamente tramite CASCADE, meno le tabelle che non fanno parte della sottoscrizione. Funzionerà correttamente se tutte le tabelle interessate fanno parte della stessa sottoscrizione. Ma se alcune tabelle da troncare sull'abbonato hanno collegamenti di chiave esterna a tabelle che non fanno parte della stessa (o qualsiasi) sottoscrizione, l'applicazione dell'azione tronca sull'abbonato avrà esito negativo.
- Gli oggetti di grandi dimensioni non vengono replicati. Non esiste una soluzione alternativa, a parte la memorizzazione dei dati in tabelle normali.
- La replica è possibile solo dalle tabelle di base alle tabelle di base. Ovvero, le tabelle sul lato pubblicazione e sottoscrizione devono essere tabelle normali, non viste, viste materializzate, tabelle radice di partizione o tabelle esterne. Nel caso delle partizioni, puoi replicare una gerarchia di partizioni uno a uno, ma al momento non puoi replicare su una configurazione partizionata in modo diverso.
Conclusione
Mantenere aggiornato il tuo server PostgreSQL eseguendo aggiornamenti regolari è stato un compito necessario ma difficile fino alla versione 10 di PostgreSQL.
In questo blog abbiamo fatto una breve introduzione alla replica logica, una funzionalità di PostgreSQL introdotta nativamente nella versione 10, e ti abbiamo mostrato come può aiutarti a superare questa sfida con una strategia a zero tempi di inattività.