La conoscenza della replica è un must per chiunque gestisca database. È un argomento che probabilmente hai visto più e più volte ma non invecchia mai. In questo blog, esamineremo un po' la storia delle funzionalità di replica integrate di PostgreSQL e approfondiremo il funzionamento della replica in streaming.
Quando si parla di replica, parleremo molto di WAL. Quindi, esaminiamo rapidamente un po' i registri write-ahead.
Registro di scrittura anticipata (WAL)
Un registro write-ahead è un metodo standard per garantire l'integrità dei dati ed è abilitato automaticamente per impostazione predefinita.
I WAL sono i log REDO in PostgreSQL. Ma cosa sono esattamente i registri REDO?
I registri REDO contengono tutte le modifiche apportate al database e vengono utilizzati per la replica, il ripristino, il backup in linea e il ripristino point-in-time (PITR). Eventuali modifiche che non sono state applicate alle pagine dati possono essere ripristinate dai registri REDO.
L'utilizzo di WAL comporta un numero significativamente ridotto di scritture su disco perché solo il file di registro deve essere scaricato su disco per garantire che una transazione sia stata salvata, piuttosto che ogni file di dati modificato dalla transazione.
Un record WAL specificherà le modifiche apportate ai dati, bit per bit. Ciascun record WAL verrà aggiunto a un file WAL. La posizione di inserimento è un Log Sequence Number (LSN), un byte spostato nei log, che aumenta con ogni nuovo record.
I WAL sono archiviati nella directory pg_wal (o pg_xlog nelle versioni PostgreSQL <10) nella directory dei dati. Questi file hanno una dimensione predefinita di 16 MB (è possibile modificare la dimensione modificando l'opzione di configurazione --with-wal-segsize durante la creazione del server). Hanno un nome incrementale univoco nel seguente formato:"00000001 00000000 00000000".
Il numero di file WAL contenuti in pg_wal dipenderà dal valore assegnato al parametro checkpoint_segments (o min_wal_size e max_wal_size, a seconda della versione) nel file di configurazione postgresql.conf.
Un parametro che devi impostare durante la configurazione di tutte le tue installazioni PostgreSQL è wal_level. wal_level determina quante informazioni vengono scritte nel WAL. Il valore predefinito è minimo, che scrive solo le informazioni necessarie per il ripristino da un arresto anomalo o dall'arresto immediato. L'archivio aggiunge la registrazione richiesta per l'archiviazione WAL; hot_standby aggiunge inoltre le informazioni necessarie per eseguire query di sola lettura su un server in standby; logical aggiunge le informazioni necessarie per supportare la decodifica logica. Questo parametro richiede un riavvio, quindi può essere difficile modificare i database di produzione in esecuzione se te ne sei dimenticato.
Per ulteriori informazioni, puoi consultare la documentazione ufficiale qui o qui. Ora che abbiamo coperto il WAL, esaminiamo la cronologia della replica in PostgreSQL.
Cronologia della replica in PostgreSQL
Il primo metodo di replica (warm standby) implementato da PostgreSQL (versione 8.2, nel 2006) era basato sul metodo di log shipping.
Ciò significa che i record WAL vengono spostati direttamente da un server di database a un altro per essere applicati. Possiamo dire che è un PITR continuo.
PostgreSQL implementa il log shipping basato su file trasferendo i record WAL un file (segmento WAL) alla volta.
Questa implementazione di replica ha lo svantaggio:se si verifica un errore grave sui server primari, le transazioni non ancora spedite andranno perse. Quindi, c'è una finestra per la perdita di dati (puoi regolarla usando il parametro archive_timeout, che può essere impostato su un minimo di pochi secondi. Tuttavia, un'impostazione così bassa aumenterà sostanzialmente la larghezza di banda richiesta per la spedizione dei file).
Possiamo rappresentare questo metodo di spedizione dei log basato su file con l'immagine qui sotto:
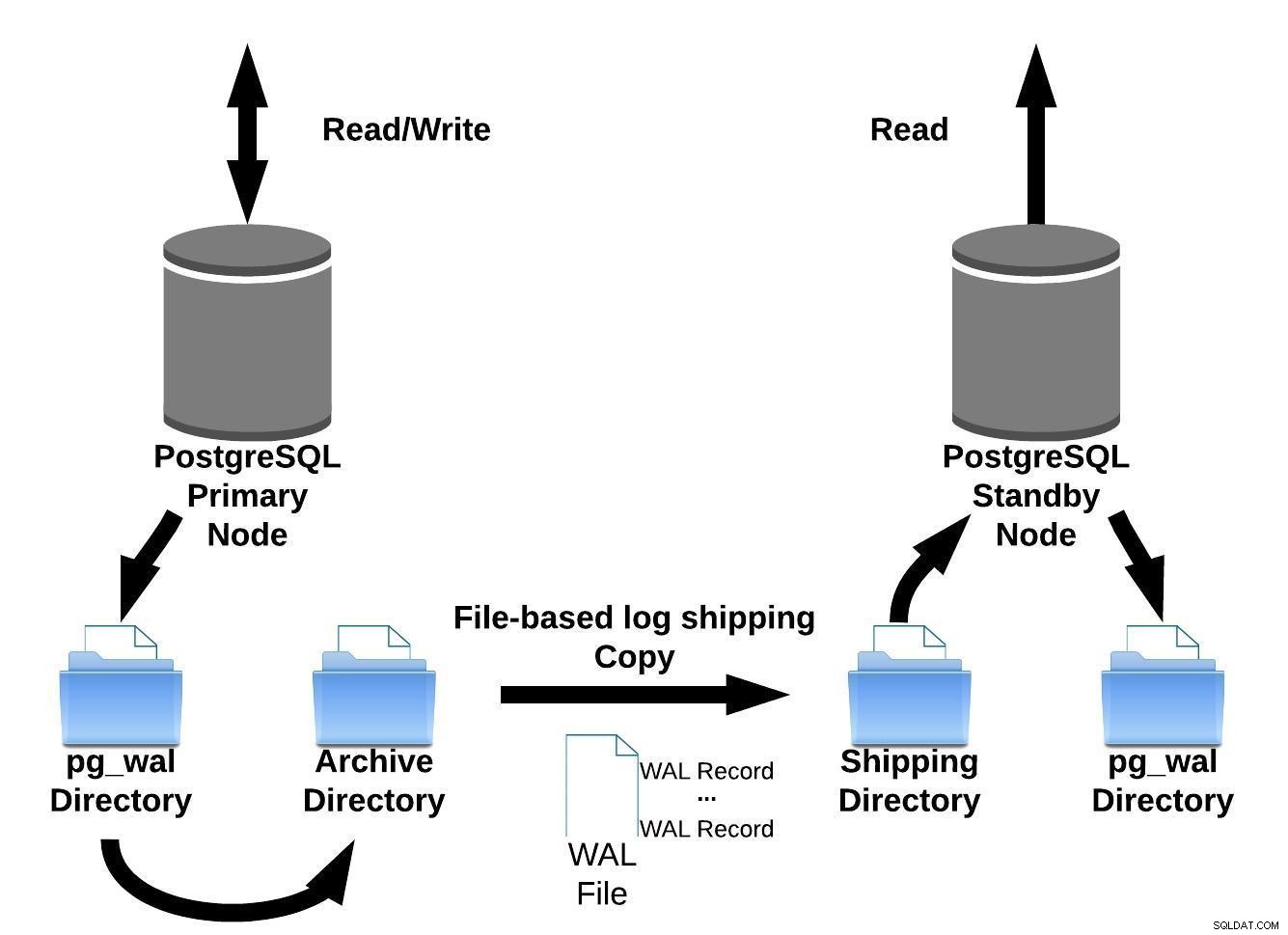 Spedizione di log basata su file PostgreSQL
Spedizione di log basata su file PostgreSQLQuindi, nella versione 9.0 (nel 2010 ), è stata introdotta la replica in streaming.
La replica in streaming ti consente di rimanere più aggiornato di quanto sia possibile con il log shipping basato su file. Funziona trasferendo i record WAL (un file WAL è composto da record WAL) al volo (log shipping basato su record) tra un server primario e uno o più server in standby senza attendere che il file WAL venga compilato.
In pratica, un processo chiamato ricevitore WAL, in esecuzione sul server di standby, si connetterà al server primario utilizzando una connessione TCP/IP. Nel server primario esiste un altro processo, denominato WAL sender, che ha il compito di inviare i registri WAL al server di standby man mano che si verificano.
Il diagramma seguente rappresenta la replica in streaming:
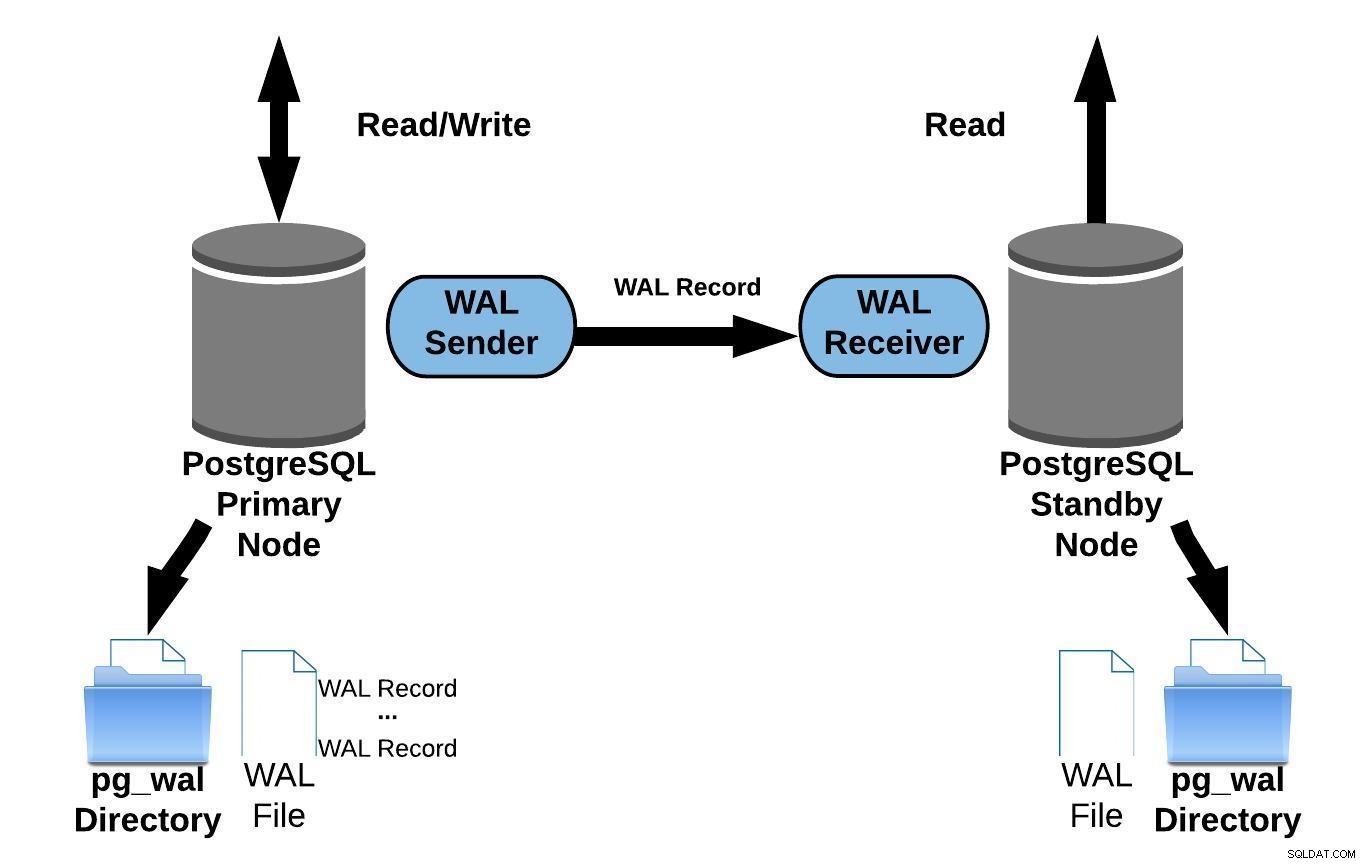 Replica PostgreSQL Streaming
Replica PostgreSQL StreamingGuardando il diagramma sopra, potresti chiederti cosa succede quando la comunicazione tra il mittente WAL e il destinatario WAL non riesce?
Quando si configura la replica in streaming, è possibile abilitare l'archiviazione WAL.
Questo passaggio non è obbligatorio ma è estremamente importante per una solida configurazione della replica. È necessario evitare che il server principale ricicli i vecchi file WAL che non sono stati ancora applicati al server di standby. In questo caso, dovrai ricreare la replica da zero.
Quando si configura la replica con archiviazione continua, inizia da un backup. Per raggiungere lo stato di sincronizzazione con il primario, è necessario applicare tutte le modifiche ospitate nel WAL che si sono verificate dopo il backup. Durante questo processo, lo standby ripristinerà prima tutto il WAL disponibile nella posizione dell'archivio (eseguito chiamando restore_command). Il restore_command fallirà quando raggiunge l'ultimo record WAL archiviato, quindi, dopodiché, lo standby cercherà nella directory pg_wal per vedere se la modifica esiste lì (funziona per evitare la perdita di dati quando i server primari si bloccano e alcune modifiche che sono già stati spostati e applicati alla replica non sono stati ancora archiviati).
Se non riesce e il record richiesto non esiste, inizierà a comunicare con il server primario tramite la replica in streaming.
Ogni volta che la replica in streaming non riesce, tornerà al passaggio 1 e ripristinerà nuovamente i record dall'archivio. Questo ciclo di tentativi dall'archivio, pg_wal, e tramite la replica in streaming continua fino all'arresto del server o finché il failover non viene attivato da un file trigger.
Il diagramma seguente rappresenta una configurazione di replica in streaming con archiviazione continua:
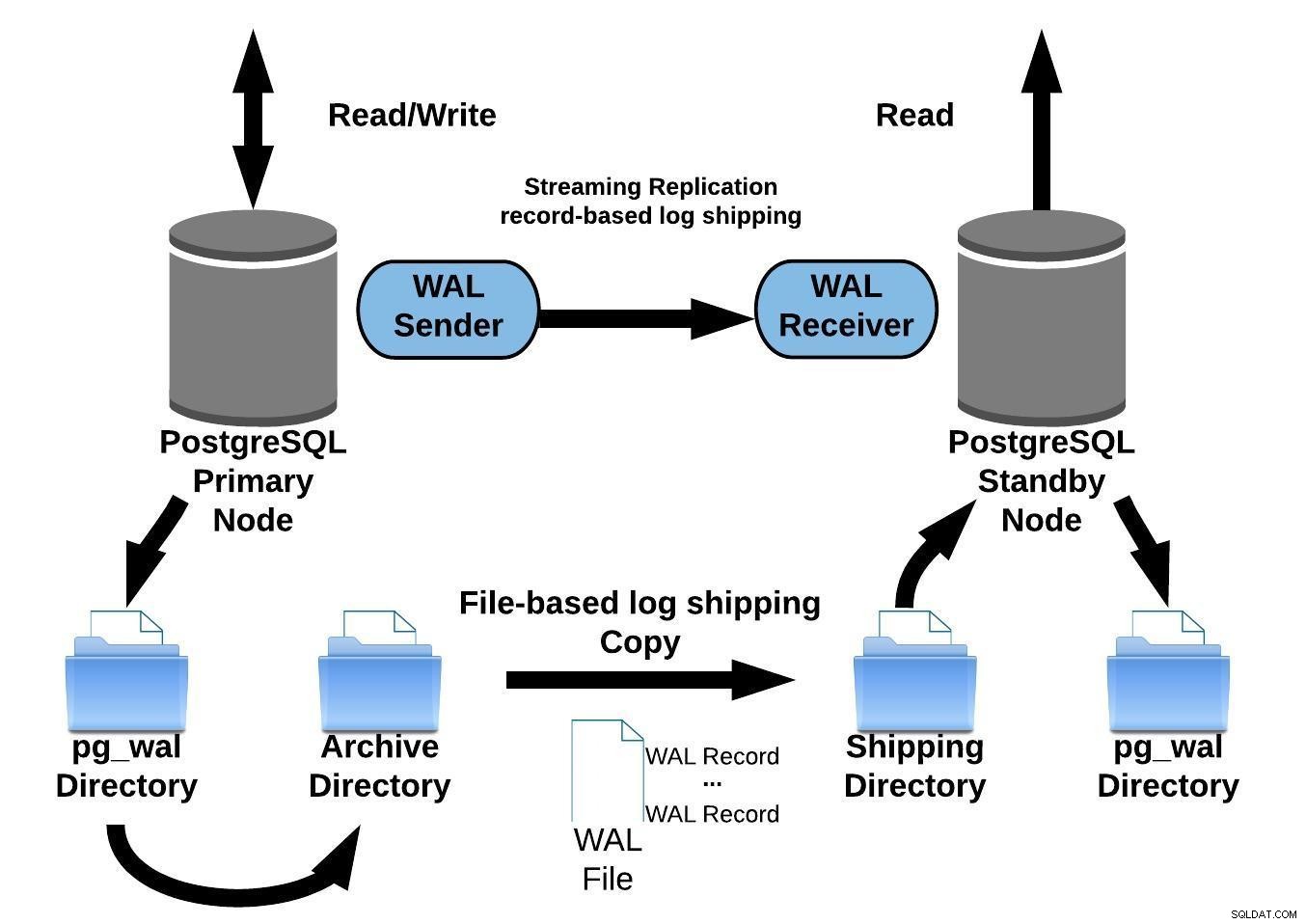 Replica in streaming PostgreSQL con archiviazione continua
Replica in streaming PostgreSQL con archiviazione continuaLa replica in streaming è asincrona per impostazione predefinita, quindi a in un dato momento, è possibile avere alcune transazioni che possono essere impegnate sul server primario e non ancora replicate sul server di standby. Ciò implica una potenziale perdita di dati.
Tuttavia, questo ritardo tra il commit e l'impatto delle modifiche nella replica dovrebbe essere davvero piccolo (alcuni millisecondi), supponendo, ovviamente, che il server di replica sia abbastanza potente da tenere il passo il carico.
Per i casi in cui anche il rischio di una leggera perdita di dati non è accettabile, la versione 9.1 ha introdotto la funzione di replica sincrona.
Nella replica sincrona, ogni commit di una transazione di scrittura attende fino a quando non viene ricevuta la conferma che il commit è stato scritto nel registro write-ahead sul disco del server primario e di standby.
Questo metodo riduce al minimo la possibilità di perdita di dati; affinché ciò avvenga, sarà necessario che sia il primario che lo standby si guastino contemporaneamente.
L'ovvio svantaggio di questa configurazione è che il tempo di risposta per ogni transazione di scrittura aumenta, poiché è necessario attendere che tutte le parti abbiano risposto. Quindi, il tempo per un commit è, come minimo, il viaggio di andata e ritorno tra il primario e la replica. Le transazioni di sola lettura non saranno interessate da questo.
Per impostare la replica sincrona, è necessario specificare un nome_applicazione in primary_conninfo del ripristino per ogni file server.conf di standby:primary_conninfo ='...aplication_name=standbyX' .
È inoltre necessario specificare l'elenco dei server in standby che prenderanno parte alla replica sincrona:synchronous_standby_name ='standbyX,standbyY'.
Puoi impostare uno o più server sincroni e questo parametro specifica anche quale metodo (FIRST e ANY) scegliere gli standby sincroni tra quelli elencati. Per ulteriori informazioni sull'impostazione della modalità di replica sincrona, consulta questo blog. È anche possibile impostare la replica sincrona durante la distribuzione tramite ClusterControl.
Dopo aver configurato la replica e averla installata e funzionante, dovrai implementare il monitoraggio
Monitoraggio della replica PostgreSQL
La vista pg_stat_replication sul server master contiene molte informazioni rilevanti:
postgres=# SELECT * FROM pg_stat_replication;
-[ RECORD 1 ]----+------------------------------
pid | 756
usesysid | 16385
usename | cmon_replication
application_name | pgsql_0_node_0
client_addr | 10.10.10.137
client_hostname |
client_port | 36684
backend_start | 2022-04-13 17:45:56.517518+00
backend_xmin |
state | streaming
sent_lsn | 0/400001C0
write_lsn | 0/400001C0
flush_lsn | 0/400001C0
replay_lsn | 0/400001C0
write_lag |
flush_lag |
replay_lag |
sync_priority | 0
sync_state | async
reply_time | 2022-04-13 17:53:03.454864+00Vediamo questo in dettaglio:
-
pid:ID processo del processo walsender.
-
usesysid:OID dell'utente utilizzato per la replica in streaming.
-
usename:nome dell'utente utilizzato per la replica in streaming.
-
application_name:nome dell'applicazione collegata al master.
-
client_addr:indirizzo di replica standby/streaming.
-
client_hostname:nome host di standby.
-
porta_client:numero della porta TCP su cui si sta comunicando con il mittente WAL.
-
backend_start:ora di inizio quando SR si è connesso a Primary.
-
stato:stato del mittente WAL corrente, ovvero streaming.
-
sent_lsn:posizione dell'ultima transazione inviata in standby.
-
write_lsn:ultima transazione scritta su disco in standby.
-
flush_lsn:ultima transazione scaricata su disco in standby.
-
replay_lsn:ultima transazione scaricata su disco in standby.
-
sync_priority:priorità del server standby scelto come standby sincrono.
-
sync_state:stato di sincronizzazione in standby (asincrono o sincrono).
Puoi anche vedere i processi mittente/destinatario WAL in esecuzione sui server.
Mittente (nodo primario):
[example@sqldat.com ~]# ps aux |grep postgres
postgres 727 0.0 2.2 917060 47936 ? Ss 17:45 0:00 /usr/pgsql-14/bin/postmaster -D /var/lib/pgsql/14/data/
postgres 732 0.0 0.2 351904 5280 ? Ss 17:45 0:00 postgres: 14/main: logger
postgres 734 0.0 0.5 917188 10560 ? Ss 17:45 0:00 postgres: 14/main: checkpointer
postgres 735 0.0 0.4 917208 9908 ? Ss 17:45 0:00 postgres: 14/main: background writer
postgres 736 0.0 1.0 917060 22928 ? Ss 17:45 0:00 postgres: 14/main: walwriter
postgres 737 0.0 0.4 917748 9128 ? Ss 17:45 0:00 postgres: 14/main: autovacuum launcher
postgres 738 0.0 0.3 917060 6320 ? Ss 17:45 0:00 postgres: 14/main: archiver last was 00000001000000000000003F
postgres 739 0.0 0.2 354160 5340 ? Ss 17:45 0:00 postgres: 14/main: stats collector
postgres 740 0.0 0.3 917632 6892 ? Ss 17:45 0:00 postgres: 14/main: logical replication launcher
postgres 756 0.0 0.6 918252 13124 ? Ss 17:45 0:00 postgres: 14/main: walsender cmon_replication 10.10.10.137(36684) streaming 0/400001C0Ricevitore (nodo di attesa):
[example@sqldat.com ~]# ps aux |grep postgres
postgres 727 0.0 2.2 917060 47576 ? Ss 17:45 0:00 /usr/pgsql-14/bin/postmaster -D /var/lib/pgsql/14/data/
postgres 732 0.0 0.2 351904 5396 ? Ss 17:45 0:00 postgres: 14/main: logger
postgres 733 0.0 0.3 917196 6360 ? Ss 17:45 0:00 postgres: 14/main: startup recovering 000000010000000000000040
postgres 734 0.0 0.4 917060 10056 ? Ss 17:45 0:00 postgres: 14/main: checkpointer
postgres 735 0.0 0.3 917060 6304 ? Ss 17:45 0:00 postgres: 14/main: background writer
postgres 736 0.0 0.2 354160 5456 ? Ss 17:45 0:00 postgres: 14/main: stats collector
postgres 737 0.0 0.6 924532 12948 ? Ss 17:45 0:00 postgres: 14/main: walreceiver streaming 0/400001C0Un modo per verificare l'aggiornamento della replica è controllare la quantità di record WAL generati nel server primario, ma non ancora applicati nel server di standby.
Primario:
postgres=# SELECT pg_current_wal_lsn();
pg_current_wal_lsn
--------------------
0/400001C0
(1 row)In attesa:
postgres=# SELECT pg_last_wal_receive_lsn();
pg_last_wal_receive_lsn
-------------------------
0/400001C0
(1 row)
postgres=# SELECT pg_last_wal_replay_lsn();
pg_last_wal_replay_lsn
------------------------
0/400001C0
(1 row)Puoi utilizzare la seguente query nel nodo di standby per ottenere il ritardo in secondi:
postgres=# SELECT CASE WHEN pg_last_wal_receive_lsn() = pg_last_wal_replay_lsn()
THEN 0
ELSE EXTRACT (EPOCH FROM now() - pg_last_xact_replay_timestamp())
END AS log_delay;
log_delay
-----------
0
(1 row)E puoi anche vedere l'ultimo messaggio ricevuto:
postgres=# SELECT status, last_msg_receipt_time FROM pg_stat_wal_receiver;
status | last_msg_receipt_time
-----------+------------------------------
streaming | 2022-04-13 18:32:39.83118+00
(1 row)Monitoraggio della replica PostgreSQL con ClusterControl
Per monitorare il tuo cluster PostgreSQL, puoi utilizzare ClusterControl, che ti consente di monitorare ed eseguire diverse attività di gestione aggiuntive come distribuzione, backup, scale-out e altro.
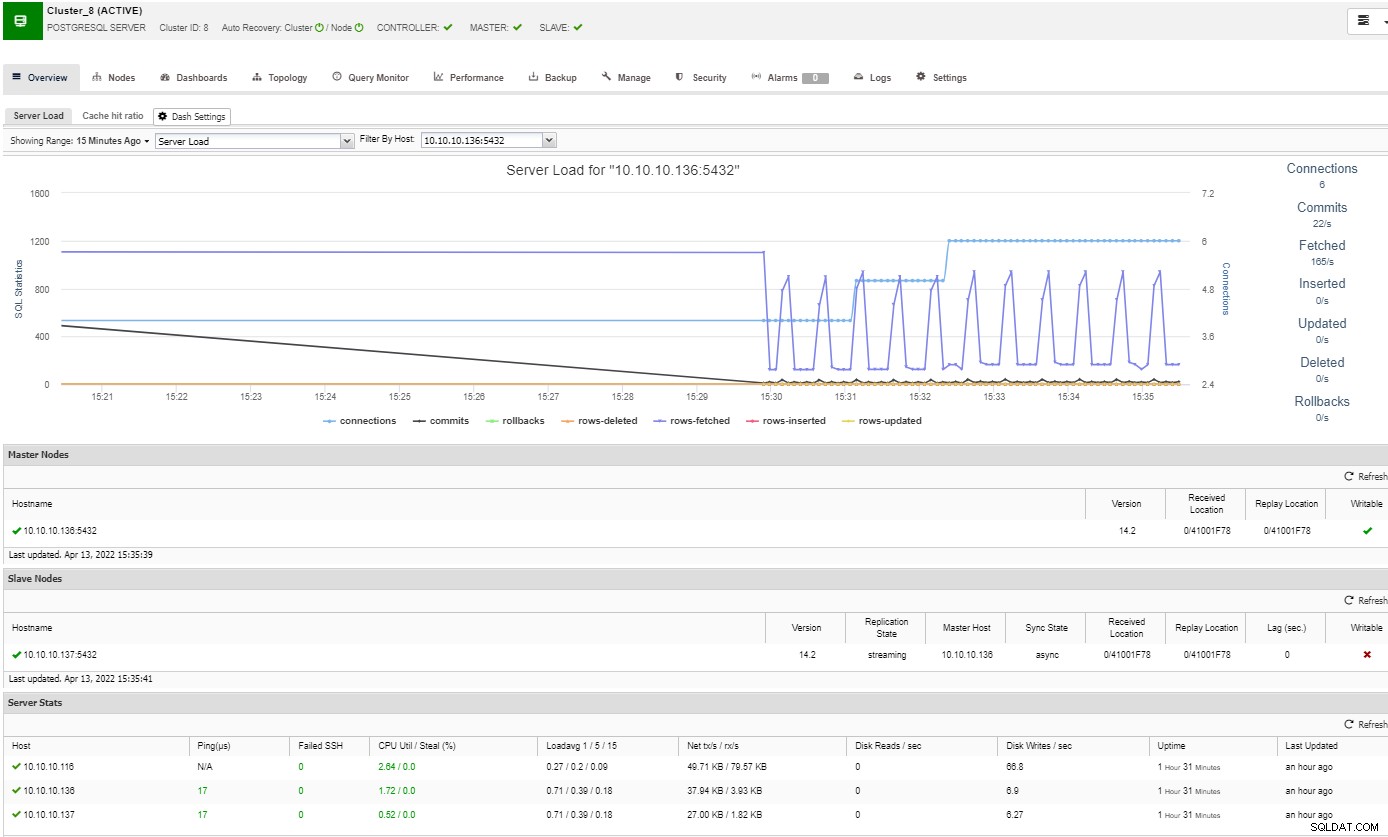
Nella sezione panoramica, avrai il quadro completo del cluster di database stato attuale. Per vedere maggiori dettagli, puoi accedere alla sezione dashboard, dove vedrai molte informazioni utili suddivise in diversi grafici.
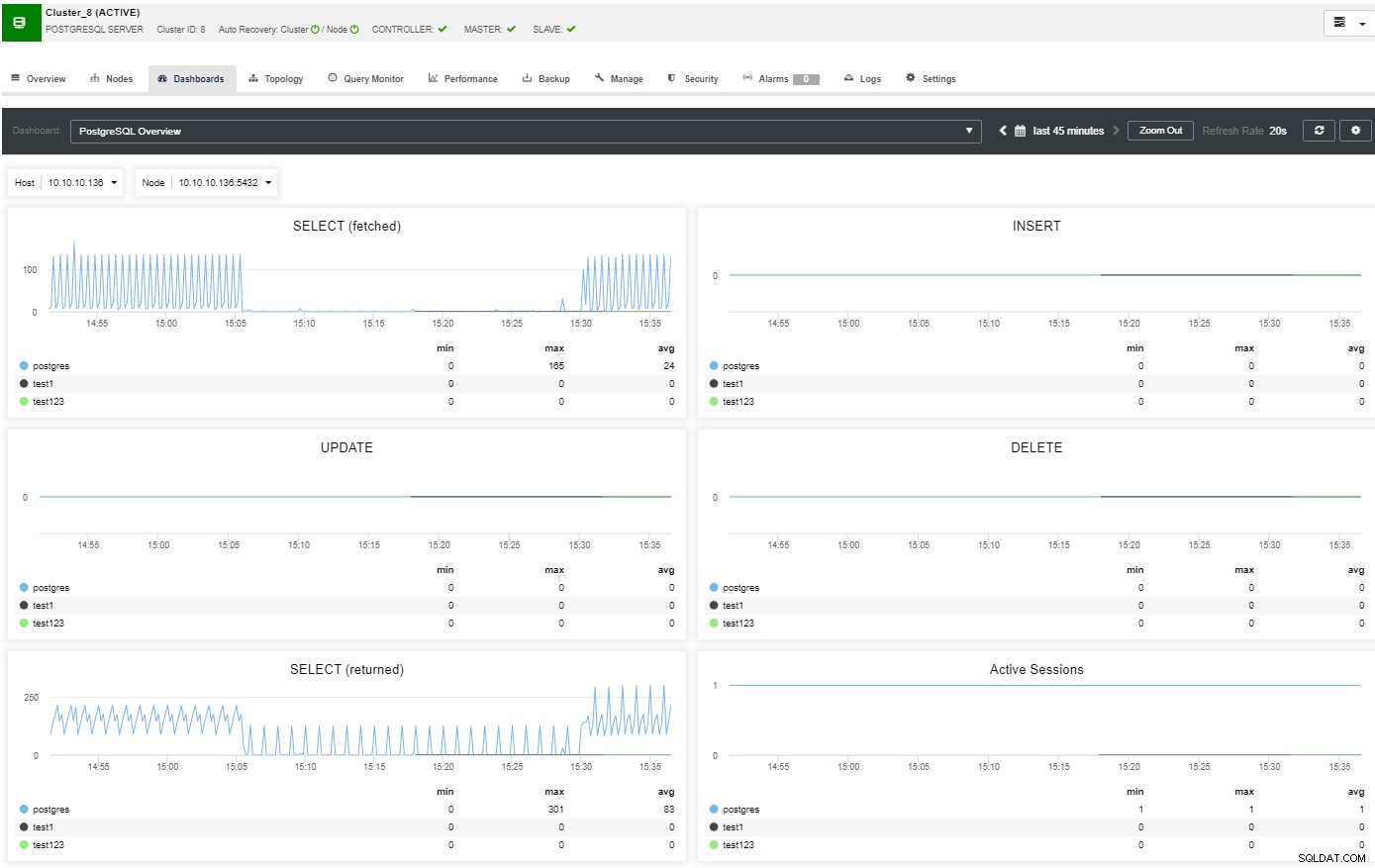
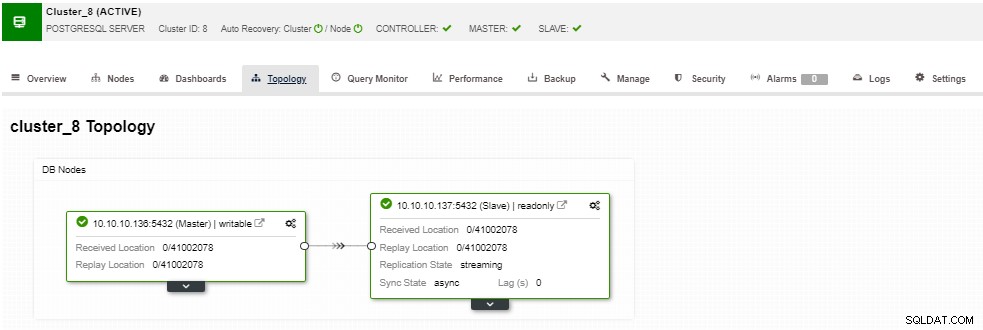
Nella sezione della topologia, puoi vedere la tua topologia attuale in un utente- modo amichevole e puoi anche eseguire diverse attività sui nodi utilizzando il pulsante Node Action.
La replica in streaming si basa sulla spedizione dei record WAL e sull'applicazione allo standby server, determina quali byte aggiungere o modificare in quale file. Di conseguenza, il server di standby è in realtà una copia bit per bit del server primario. Ci sono, tuttavia, alcune limitazioni ben note qui:
-
Non puoi replicare in una versione o architettura diversa.
-
Non puoi modificare nulla sul server di standby.
-
Non hai molta granularità su ciò che replichi.
Quindi, per superare queste limitazioni, PostgreSQL 10 ha aggiunto il supporto per la replica logica
Replica logica
La replica logica utilizzerà anche le informazioni nel file WAL, ma le decodificherà in modifiche logiche. Invece di sapere quale byte è cambiato, saprà esattamente quali dati sono stati inseriti in quale tabella.
Si basa su un modello "pubblica" e "sottoscrivi" con uno o più abbonati che si iscrivono a una o più pubblicazioni su un nodo editore simile al seguente:
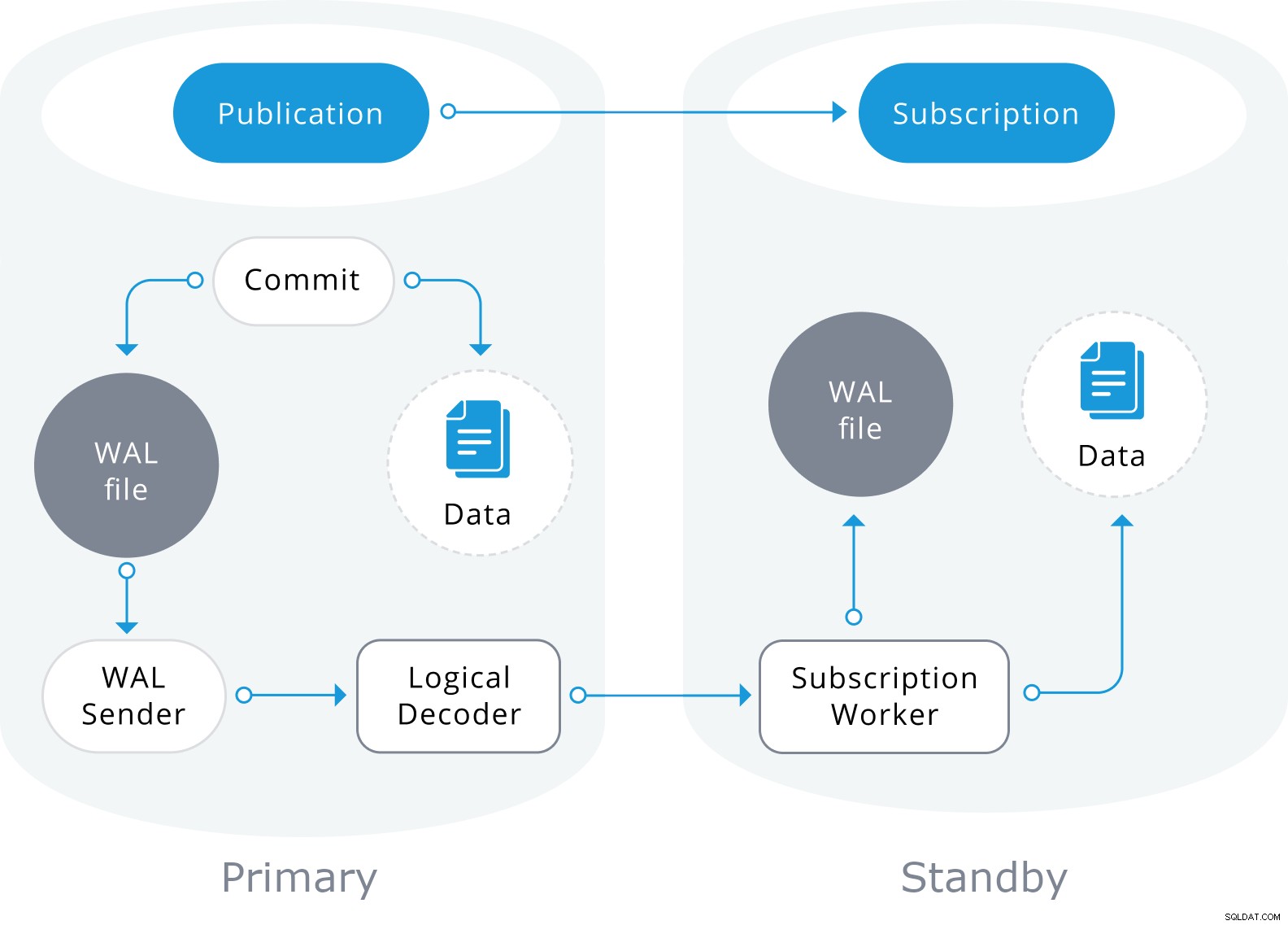
Conclusione
Con la replica in streaming, puoi inviare e applicare continuamente record WAL ai tuoi server di standby, assicurandoti che le informazioni aggiornate sul server primario vengano trasferite al server di standby in tempo reale, consentendo a entrambi di rimanere sincronizzati .
ClusterControl semplifica la configurazione della replica in streaming e puoi valutarla gratuitamente per 30 giorni.
Se vuoi saperne di più sulla replica logica in PostgreSQL, assicurati di dare un'occhiata a questa panoramica della replica logica e a questo post sulle migliori pratiche di replicazione di PostgreSQL.
Per ulteriori suggerimenti e best practice per la gestione del database open source, seguici su Twitter e LinkedIn e iscriviti alla nostra newsletter per aggiornamenti regolari.



