Questi dati sono normalizzati
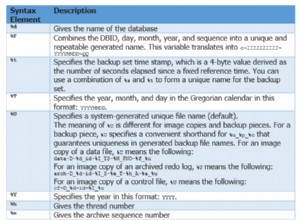
TABLE { FIELDS }
-----------------------------------------------------------------------
building { id, data }
floor { id, building_id, data }
room {id, floor_id, data }
bed {id, room_id, data }
Questa tabella non è (cattiva idea)
TABLE { FIELDS }
-----------------------------------------------------------------------
building { id, data }
floor { id, building_id, data }
room {id, building_id, floor_id, data }
bed {id, building_id, floor_id, room_id, data }
- Nella prima (buona) tabella non hai dati duplicati non necessari.
- Gli inserti nella prima tabella saranno molto più veloci.
- Le prime tabelle si adatteranno più facilmente alla memoria, velocizzando le tue query.
- InnoDB è ottimizzato pensando al modello A, non al modello B.
- L'ultima tabella (non valida) ha dati duplicati, se che non è sincronizzato, avrai un pasticcio. DB A non può essere molto più difficile da sincronizzare, perché i dati vengono elencati solo una volta.
- Se voglio combinare dati dall'edificio, dal pavimento, dalla camera e dal letto dovrò combinare tutti e quattro i tavoli nel modello A e nel modello B, come stai risparmiando tempo qui.
- InnoDB memorizza i dati indicizzati nel proprio file, se
selectsolo indici , i tavoli stessi mai essere accessibile. Allora perché duplichi gli indici? MySQL non avrà mai bisogno di leggere la tabella principale comunque. - InnoDB memorizza il PK in ogni indice secondario , con un PK composito e quindi lungo, stai rallentando ogni selezione che utilizza un indice e aumentando la dimensione del file; per nessun guadagno che cosa così mai.
- Hai seri problemi di velocità? Se no, stai denormalizzando le tue tabelle?
- Non pensare nemmeno all'utilizzo di MyISAM che soffre di meno di questi problemi, non è ottimizzato per database multi-join e non supporta l'integrità referenziale o le transazioni ed è una scarsa corrispondenza per questo carico di lavoro.
- Quando usi una chiave composita puoi sempre usare solo la parte più a destra della chiave, cioè non puoi usare
floor_idnella tabellabeddiverso dall'utilizzo diid+building_id+floor_id, Ciò significa che potrebbe essere necessario utilizzare molto più spazio per le chiavi del necessario nel Modello A. O quello o è necessario aggiungere un indice aggiuntivo (che trascinerà una copia completa del PK).
In breve
Vedo assolutamente zero vantaggi e un sacco di inconvenienti nel Modello B, non usarlo mai!