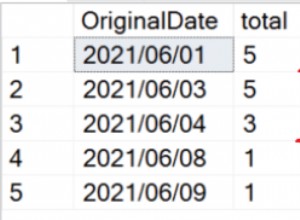
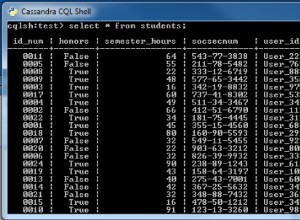
Davvero DynamoDB e MySQL sono mele e arance. DynamoDB è un livello di archiviazione NoSQL mentre MySQL viene utilizzato per l'archiviazione relazionale. Dovresti scegliere cosa usare in base alle effettive esigenze della tua applicazione. In effetti, alcune applicazioni potrebbero essere ben servite utilizzando entrambe.
Se, ad esempio, stai archiviando dati che non si prestano bene a uno schema relazionale (strutture ad albero, rappresentazioni JSON senza schema, ecc.) che possono essere ricercati rispetto a una singola chiave o a una combinazione chiave/intervallo, DynamoDB ( o qualche altro negozio NoSQL) sarebbe probabilmente la soluzione migliore.
Se hai uno schema ben definito per i tuoi dati che si adatta bene a una struttura relazionale e hai bisogno della flessibilità per interrogare i dati in diversi modi (aggiungendo indici se necessario ovviamente), allora RDS potrebbe essere una soluzione migliore .
Il vantaggio principale dell'utilizzo di DynamoDB come archivio NoSQL è che si ottiene un throughput di lettura/scrittura garantito a qualsiasi livello richiesto senza doversi preoccupare della gestione di un archivio dati in cluster. Quindi, se la tua applicazione richiede 1000 letture/scritture al secondo, puoi semplicemente effettuare il provisioning della tua tabella DynamoDB per quel livello di throughput e non devi preoccuparti dell'infrastruttura sottostante.
RDS ha lo stesso vantaggio di non doversi preoccupare dell'infrastruttura stessa, tuttavia se finisci per dover eseguire un numero significativo di scritture al punto in cui la dimensione dell'istanza più grande non reggerà più, rimarrai senza opzioni (è possibile ridimensionare orizzontalmente per le letture utilizzando le repliche di lettura).
Nota aggiornata:DynamoDb ora supporta l'indicizzazione secondaria globale, quindi ora hai la possibilità di eseguire ricerche ottimizzate su campi di dati diversi dall'hash o dalla combinazione di chiavi hash e intervallo.