Mysqldump è lo strumento di backup logico più popolare per MySQL. È incluso nella distribuzione MySQL, quindi è pronto per l'uso su tutte le istanze MySQL.
I backup logici non sono, tuttavia, il modo più veloce né il più efficiente in termini di spazio per eseguire il backup dei database MySQL, ma hanno un enorme vantaggio rispetto ai backup fisici.
I backup fisici sono in genere tutti o niente tipi di backup. Sebbene sia possibile creare un backup parziale con Xtrabackup (l'abbiamo descritto in uno dei nostri post precedenti sul blog), il ripristino di tale backup è complicato e richiede tempo.
Fondamentalmente, se vogliamo ripristinare una singola tabella, dobbiamo fermare l'intera catena di replica ed eseguire il ripristino su tutti i nodi contemporaneamente. Questo è un grosso problema:al giorno d'oggi raramente puoi permetterti di bloccare tutti i database.
Un altro problema è che il livello della tabella è il livello di granularità più basso che puoi ottenere con Xtrabackup:puoi ripristinare una singola tabella ma non puoi ripristinarne una parte. Il backup logico, tuttavia, può essere ripristinato nel modo di eseguire istruzioni SQL, quindi può essere facilmente eseguito su un cluster in esecuzione e puoi (non lo chiameremmo facilmente, ma comunque) scegliere quali istruzioni SQL eseguire in modo da poter eseguire un ripristino parziale di una tabella.
Diamo un'occhiata a come questo può essere fatto nel mondo reale.
Ripristino di una singola tabella MySQL utilizzando mysqldump
All'inizio, tieni presente che i backup parziali non forniscono una visualizzazione coerente dei dati. Quando si eseguono backup di tabelle separate, non è possibile ripristinare tale backup in una posizione nota nel tempo (ad esempio, per eseguire il provisioning dello slave di replica) anche se si ripristinano tutti i dati dal backup. Avendo questo alle spalle, procediamo.
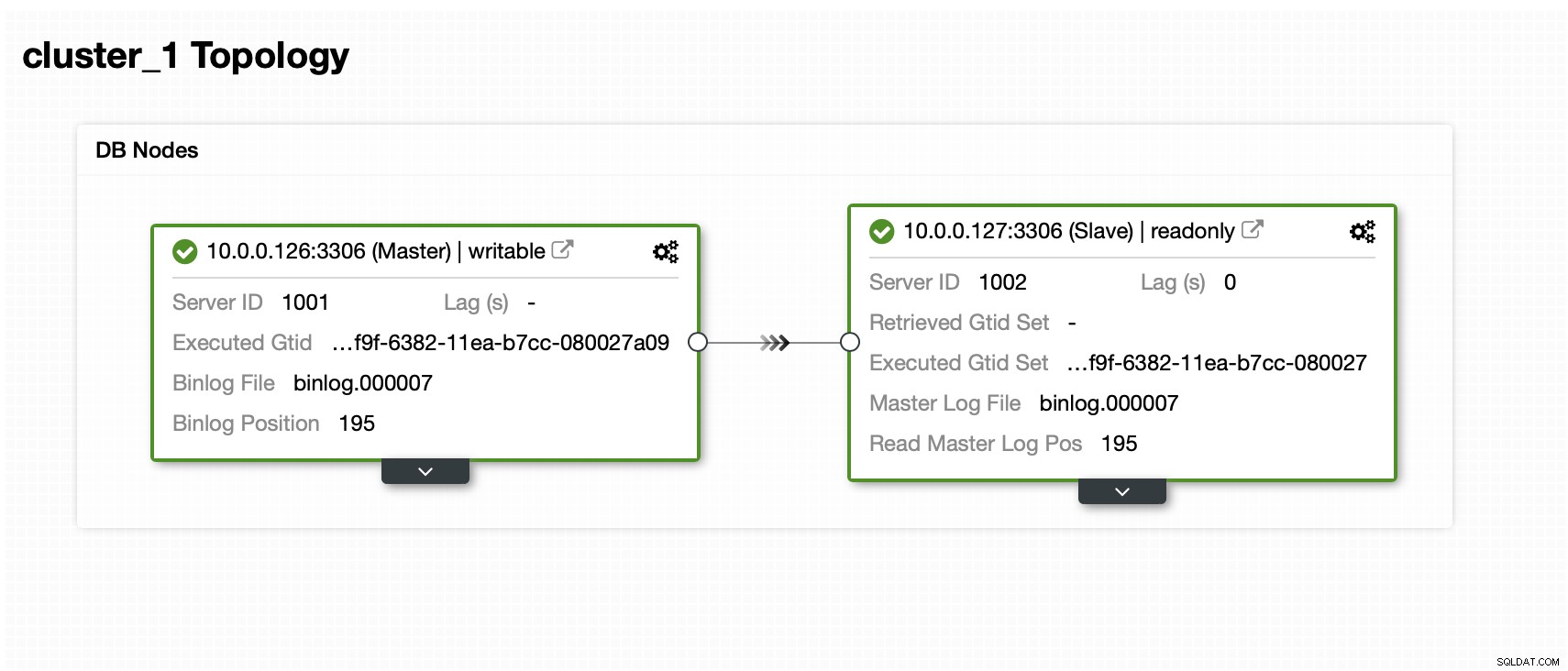
Abbiamo un master e uno slave:
Il set di dati contiene uno schema e diverse tabelle:
mysql> SHOW SCHEMAS;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| sbtest |
| sys |
+--------------------+
5 rows in set (0.01 sec)
mysql> SHOW TABLES FROM sbtest;
+------------------+
| Tables_in_sbtest |
+------------------+
| sbtest1 |
| sbtest10 |
| sbtest11 |
| sbtest12 |
| sbtest13 |
| sbtest14 |
| sbtest15 |
| sbtest16 |
| sbtest17 |
| sbtest18 |
| sbtest19 |
| sbtest2 |
| sbtest20 |
| sbtest21 |
| sbtest22 |
| sbtest23 |
| sbtest24 |
| sbtest25 |
| sbtest26 |
| sbtest27 |
| sbtest28 |
| sbtest29 |
| sbtest3 |
| sbtest30 |
| sbtest31 |
| sbtest32 |
| sbtest4 |
| sbtest5 |
| sbtest6 |
| sbtest7 |
| sbtest8 |
| sbtest9 |
+------------------+
32 rows in set (0.00 sec)Ora dobbiamo fare un backup. Ci sono diversi modi in cui possiamo affrontare questo problema. Possiamo semplicemente fare un backup coerente dell'intero set di dati, ma questo genererà un unico file grande con tutti i dati. Per ripristinare la singola tabella dovremmo estrarre i dati per la tabella da quel file. Ovviamente è possibile, ma richiede molto tempo ed è praticamente un'operazione manuale che può essere eseguita tramite script, ma se non si dispone di script adeguati, scrivere codice ad hoc quando il database è inattivo e si è sottoposti a forti pressioni è non è necessariamente l'idea più sicura.
Invece di ciò possiamo preparare il backup in modo che ogni tabella venga archiviata in un file separato:
example@sqldat.com:~/backup# d=$(date +%Y%m%d) ; db='sbtest'; for tab in $(mysql -uroot -ppass -h127.0.0.1 -e "SHOW TABLES FROM ${db}" | grep -v Tables_in_${db}) ; do mysqldump --set-gtid-purged=OFF --routines --events --triggers ${db} ${tab} > ${d}_${db}.${tab}.sql ; doneTieni presente che abbiamo impostato --set-gtid-purged=OFF. Ne abbiamo bisogno se dovessimo caricare questi dati in un secondo momento nel database. Altrimenti MySQL tenterà di impostare @@GLOBAL.GTID_PURGED, che molto probabilmente fallirà. MySQL potrebbe anche impostare SET @@SESSION.SQL_LOG_BIN=0; che sicuramente non è quello che vogliamo. Tali impostazioni sono necessarie se desideriamo eseguire un backup coerente dell'intero set di dati e vorremmo utilizzarlo per eseguire il provisioning di un nuovo nodo. Nel nostro caso sappiamo che non è un backup coerente e non è possibile ricostruire nulla da esso. Tutto ciò che vogliamo è generare un dump che possiamo caricare sul master e lasciarlo replicare sugli slave.
Quel comando ha generato una bella lista di file sql che possono essere caricati nel cluster di produzione:
example@sqldat.com:~/backup# ls -alh
total 605M
drwxr-xr-x 2 root root 4.0K Mar 18 14:10 .
drwx------ 9 root root 4.0K Mar 18 14:08 ..
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest10.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest11.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest12.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest13.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest14.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest15.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest16.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest17.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest18.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest19.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest1.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest20.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest21.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest22.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest23.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest24.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest25.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest26.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest27.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest28.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest29.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest2.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest30.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest31.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest32.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest3.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest4.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest5.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest6.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest7.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest8.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest9.sqlQuando desideri ripristinare i dati, tutto ciò che devi fare è caricare il file SQL nel nodo master:
example@sqldat.com:~/backup# mysql -uroot -ppass sbtest < 20200318_sbtest.sbtest11.sqlI dati verranno caricati nel database e replicati su tutti gli slave.
Come ripristinare una singola tabella MySQL utilizzando ClusterControl?
Attualmente ClusterControl non fornisce un modo semplice per ripristinare una singola tabella, ma è comunque possibile farlo con poche azioni manuali. Ci sono due opzioni che puoi usare. Innanzitutto, adatto per un numero limitato di tabelle, puoi sostanzialmente creare una pianificazione in cui esegui backup parziali di tabelle separate una per una:
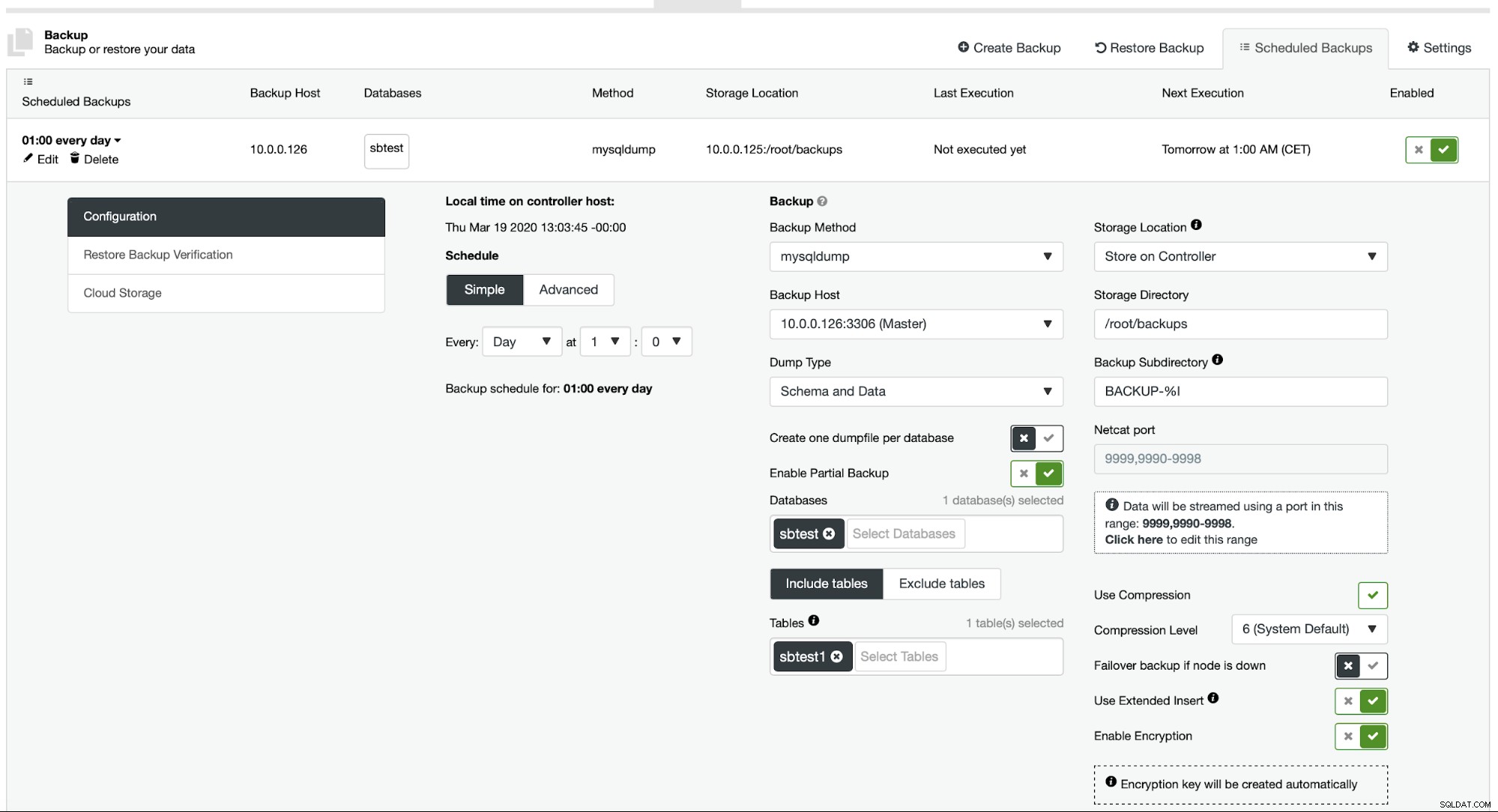
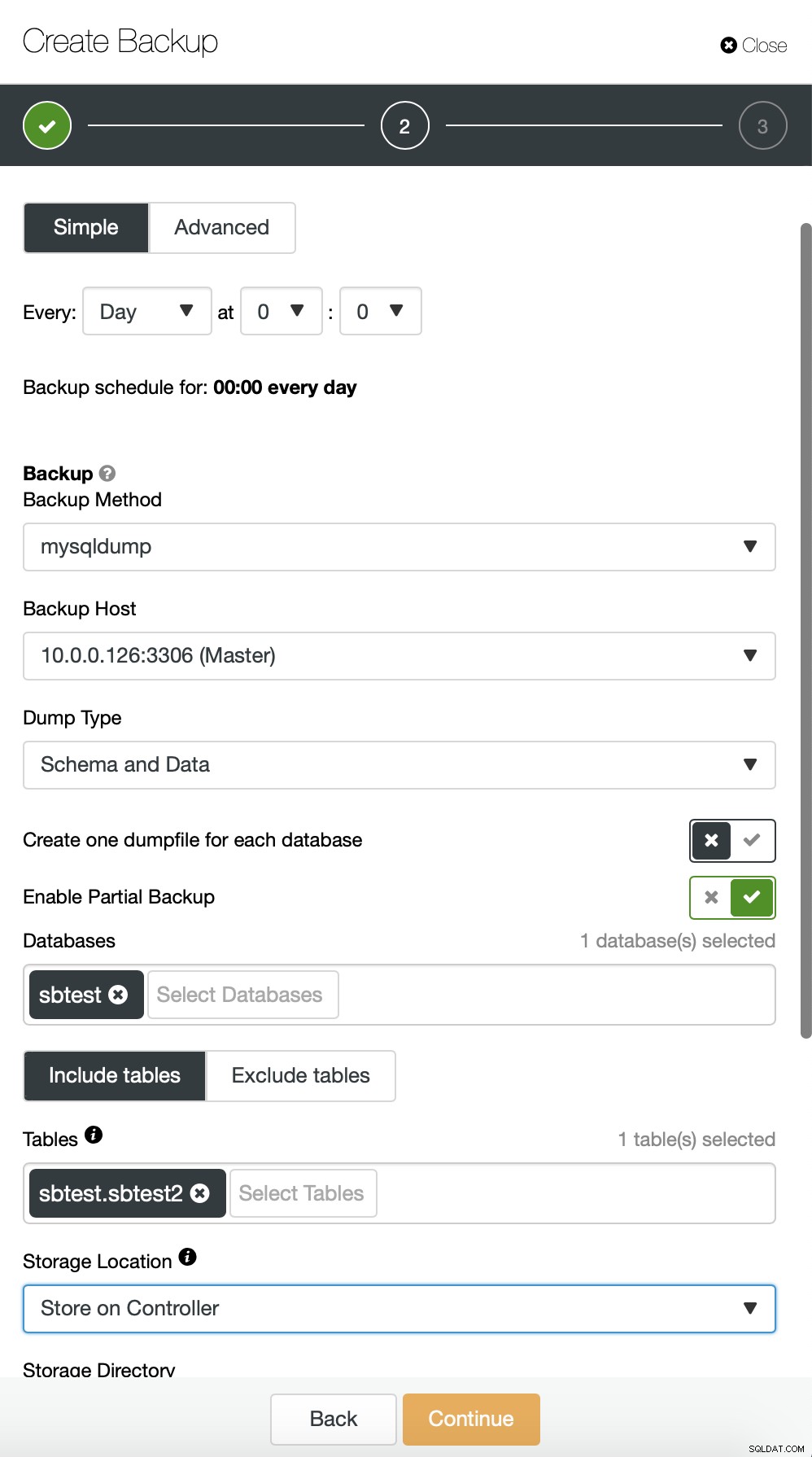
Qui stiamo facendo un backup della tabella sbtest.sbtest1. Possiamo facilmente pianificare un altro backup per la tabella sbtest2:
In alternativa possiamo eseguire un backup e inserire i dati da un singolo schema in un file separato:
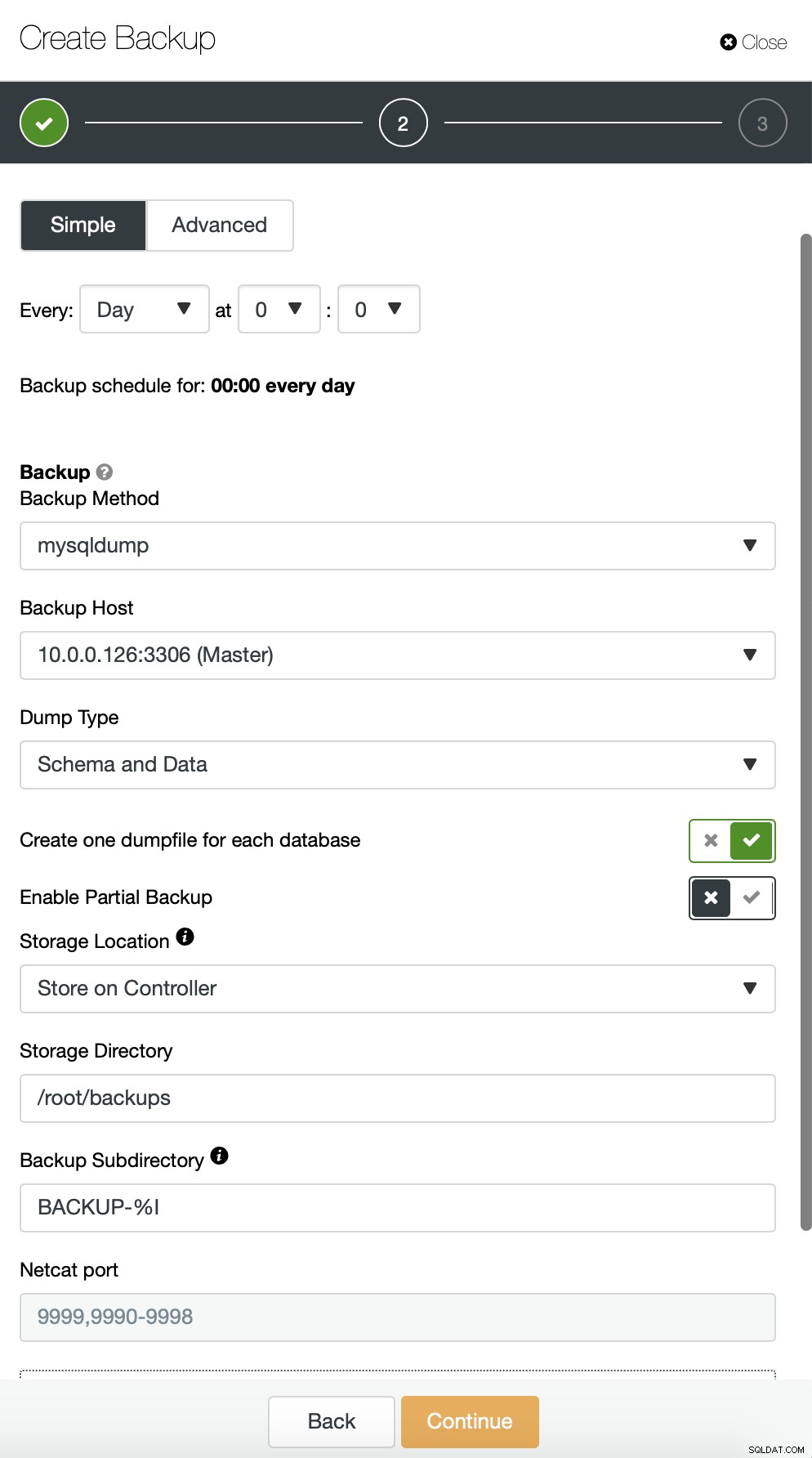
Ora puoi trovare manualmente i dati mancanti nel file, ripristinare questo backup su un server separato o lascia che ClusterControl lo faccia:
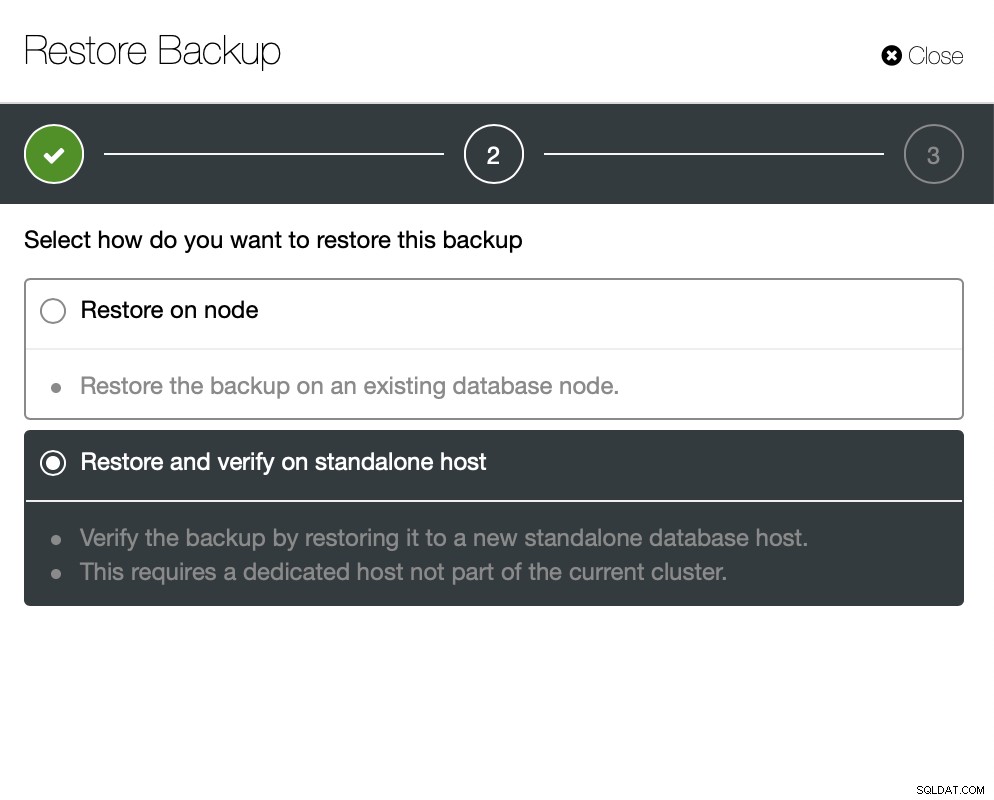
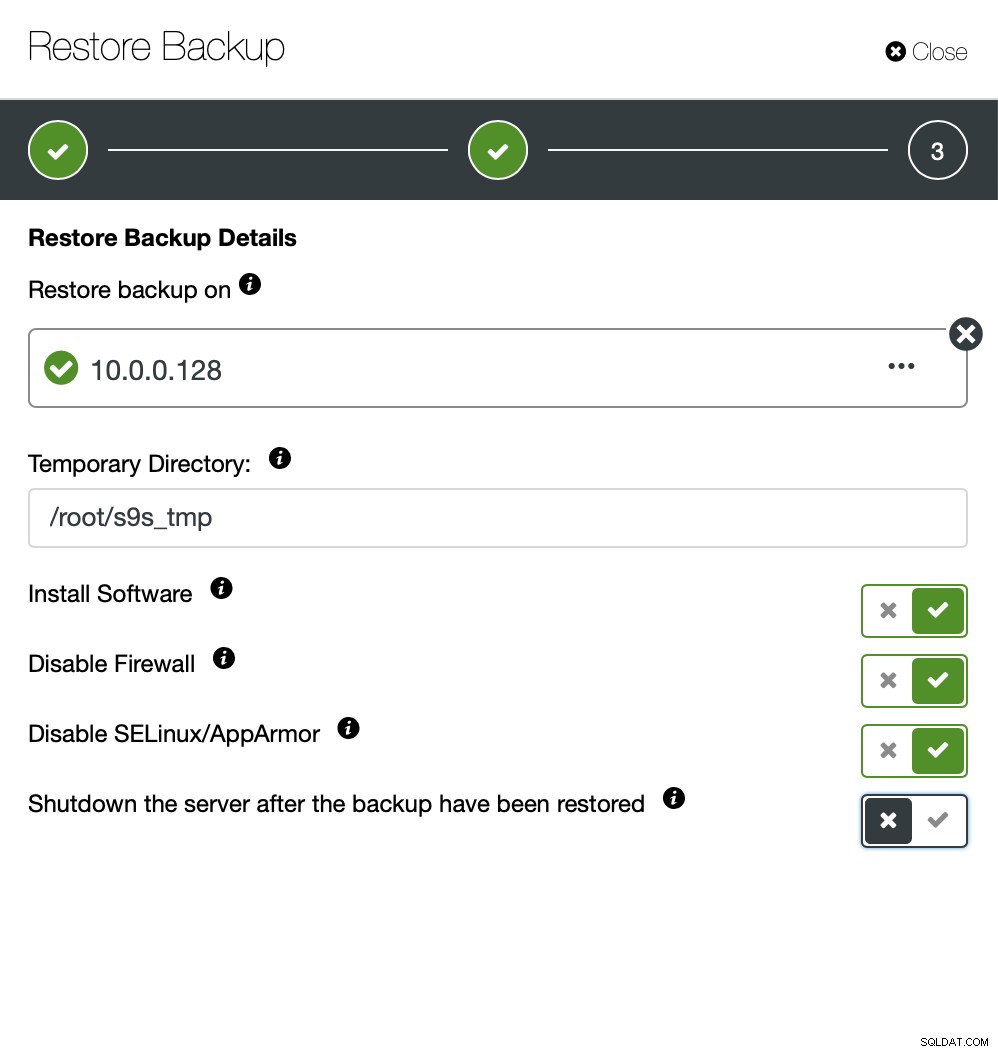
Mantieni il server attivo e funzionante e puoi estrarre i dati che volevo ripristinare usando mysqldump o SELECT … INTO OUTFILE. Tali dati estratti saranno pronti per essere applicati al cluster di produzione.



