Nella prima parte di questo blog, abbiamo trattato una procedura dettagliata per la distribuzione di MySQL InnoDB Cluster con un esempio su come le applicazioni possono connettersi al cluster tramite una porta di lettura/scrittura dedicata.
In questa procedura dettagliata, mostreremo esempi su come monitorare, gestire e ridimensionare il cluster InnoDB come parte delle operazioni di manutenzione del cluster in corso. Utilizzeremo lo stesso cluster che abbiamo distribuito nella prima parte del blog. Il diagramma seguente mostra la nostra architettura:
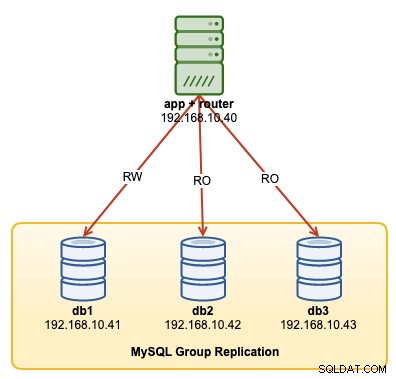
Abbiamo una replica del gruppo MySQL a tre nodi e un server delle applicazioni in esecuzione con Router MySQL. Tutti i server funzionano su Ubuntu 18.04 Bionic.
Opzioni dei comandi del cluster MySQL InnoDB
Prima di passare oltre con alcuni esempi e spiegazioni, è bene sapere che puoi ottenere una spiegazione di ciascuna funzione nel cluster MySQL per il componente cluster utilizzando la funzione help(), come mostrato di seguito:
$ mysqlsh
MySQL|localhost:3306 ssl|JS> shell.connect("example@sqldat.com:3306");
MySQL|db1:3306 ssl|JS> cluster = dba.getCluster();
<Cluster:my_innodb_cluster>
MySQL|db1:3306 ssl|JS> cluster.help()L'elenco seguente mostra le funzioni disponibili su MySQL Shell 8.0.18, per MySQL Community Server 8.0.18:
- addInstance(instance[, options])- Aggiunge un'istanza al cluster.
- checkInstanceState(instance)- verifica lo stato gtid dell'istanza in relazione al cluster.
- describe()- Descrive la struttura del cluster.
- disconnect()- Disconnette tutte le sessioni interne utilizzate dall'oggetto cluster.
- dissolve([options])- Disattiva la replica e annulla la registrazione dei ReplicaSet dal cluster.
- forceQuorumUsingPartitionOf(instance[, password])- Ripristina il cluster dalla perdita del quorum.
- getName()- Recupera il nome del cluster.
- help([member])- Fornisce assistenza su questa classe e sui suoi membri
- options([options])- Elenca le opzioni di configurazione del cluster.
- rejoinInstance(instance[, options])- riunisce un'istanza al cluster.
- removeInstance(instance[, options])- Rimuove un'istanza dal cluster.
- rescan([options])- esegue nuovamente la scansione del cluster.
- resetRecoveryAccountsPassword(options)- Reimposta la password degli account di ripristino del cluster.
- setInstanceOption(instance, option, value)- Modifica il valore di un'opzione di configurazione in un membro del cluster.
- setOption(option, value)- Modifica il valore di un'opzione di configurazione per l'intero cluster.
- setPrimaryInstance(instance)- Elegge un membro del cluster specifico come nuovo primario.
- status([options])- Descrivi lo stato del cluster.
- switchToMultiPrimaryMode()- Passa il cluster alla modalità multi-primaria.
- switchToSinglePrimaryMode([instance])- Passa il cluster alla modalità single-primary.
Esamineremo la maggior parte delle funzioni disponibili per aiutarci a monitorare, gestire e ridimensionare il cluster.
Monitoraggio delle operazioni del cluster MySQL InnoDB
Stato del cluster
Per controllare lo stato del cluster, usa prima la riga di comando della shell MySQL e poi connettiti come esempio@sqldat.com{one-of-the-db-nodes}:
$ mysqlsh
MySQL|localhost:3306 ssl|JS> shell.connect("example@sqldat.com:3306");Quindi, crea un oggetto chiamato "cluster" e dichiaralo come oggetto globale "dba" che fornisce l'accesso alle funzioni di amministrazione del cluster InnoDB utilizzando l'AdminAPI (consulta i documenti dell'API MySQL Shell):
MySQL|db1:3306 ssl|JS> cluster = dba.getCluster();
<Cluster:my_innodb_cluster>Quindi, possiamo usare il nome dell'oggetto per chiamare le funzioni API per l'oggetto "dba":
MySQL|db1:3306 ssl|JS> cluster.status(){
"clusterName": "my_innodb_cluster",
"defaultReplicaSet": {
"name": "default",
"primary": "db1:3306",
"ssl": "REQUIRED",
"status": "OK",
"statusText": "Cluster is ONLINE and can tolerate up to ONE failure.",
"topology": {
"db1:3306": {
"address": "db1:3306",
"mode": "R/W",
"readReplicas": {},
"replicationLag": null,
"role": "HA",
"status": "ONLINE",
"version": "8.0.18"
},
"db2:3306": {
"address": "db2:3306",
"mode": "R/O",
"readReplicas": {},
"replicationLag": "00:00:09.061918",
"role": "HA",
"status": "ONLINE",
"version": "8.0.18"
},
"db3:3306": {
"address": "db3:3306",
"mode": "R/O",
"readReplicas": {},
"replicationLag": "00:00:09.447804",
"role": "HA",
"status": "ONLINE",
"version": "8.0.18"
}
},
"topologyMode": "Single-Primary"
},
"groupInformationSourceMember": "db1:3306"
}L'output è piuttosto lungo ma possiamo filtrarlo usando la struttura della mappa. Ad esempio, se desideriamo visualizzare il ritardo di replica solo per db3, potremmo fare come segue:
MySQL|db1:3306 ssl|JS> cluster.status().defaultReplicaSet.topology["db3:3306"].replicationLag
00:00:09.447804Si noti che il ritardo di replica è qualcosa che si verificherà nella replica di gruppo, a seconda dell'intensità di scrittura del membro primario nel set di repliche e delle variabili group_replication_flow_control_*. Non tratteremo questo argomento in dettaglio qui. Dai un'occhiata a questo post del blog per approfondire le prestazioni della replica di gruppo e il controllo del flusso.
Un'altra funzione simile è la funzione describe(), ma questa è un po' più semplice. Descrive la struttura del cluster comprese tutte le sue informazioni, ReplicaSet e Istanze:
MySQL|db1:3306 ssl|JS> cluster.describe(){
"clusterName": "my_innodb_cluster",
"defaultReplicaSet": {
"name": "default",
"topology": [
{
"address": "db1:3306",
"label": "db1:3306",
"role": "HA"
},
{
"address": "db2:3306",
"label": "db2:3306",
"role": "HA"
},
{
"address": "db3:3306",
"label": "db3:3306",
"role": "HA"
}
],
"topologyMode": "Single-Primary"
}
}Allo stesso modo, possiamo filtrare l'output JSON utilizzando la struttura della mappa:
MySQL|db1:3306 ssl|JS> cluster.describe().defaultReplicaSet.topologyMode
Single-PrimaryQuando il nodo primario si è interrotto (in questo caso è db1), l'output ha restituito quanto segue:
MySQL|db1:3306 ssl|JS> cluster.status(){
"clusterName": "my_innodb_cluster",
"defaultReplicaSet": {
"name": "default",
"primary": "db2:3306",
"ssl": "REQUIRED",
"status": "OK_NO_TOLERANCE",
"statusText": "Cluster is NOT tolerant to any failures. 1 member is not active",
"topology": {
"db1:3306": {
"address": "db1:3306",
"mode": "n/a",
"readReplicas": {},
"role": "HA",
"shellConnectError": "MySQL Error 2013 (HY000): Lost connection to MySQL server at 'reading initial communication packet', system error: 104",
"status": "(MISSING)"
},
"db2:3306": {
"address": "db2:3306",
"mode": "R/W",
"readReplicas": {},
"replicationLag": null,
"role": "HA",
"status": "ONLINE",
"version": "8.0.18"
},
"db3:3306": {
"address": "db3:3306",
"mode": "R/O",
"readReplicas": {},
"replicationLag": null,
"role": "HA",
"status": "ONLINE",
"version": "8.0.18"
}
},
"topologyMode": "Single-Primary"
},
"groupInformationSourceMember": "db2:3306"
}Prestare attenzione allo stato OK_NO_TOLERANCE, in cui il cluster è ancora attivo e in esecuzione ma non può tollerare ulteriori errori dopo che uno su tre nodi non è disponibile. Il ruolo principale è stato assunto automaticamente da db2 e le connessioni al database dall'applicazione verranno reindirizzate al nodo corretto se si connettono tramite MySQL Router. Una volta che db1 torna online, dovremmo vedere il seguente stato:
MySQL|db1:3306 ssl|JS> cluster.status(){
"clusterName": "my_innodb_cluster",
"defaultReplicaSet": {
"name": "default",
"primary": "db2:3306",
"ssl": "REQUIRED",
"status": "OK",
"statusText": "Cluster is ONLINE and can tolerate up to ONE failure.",
"topology": {
"db1:3306": {
"address": "db1:3306",
"mode": "R/O",
"readReplicas": {},
"replicationLag": null,
"role": "HA",
"status": "ONLINE",
"version": "8.0.18"
},
"db2:3306": {
"address": "db2:3306",
"mode": "R/W",
"readReplicas": {},
"replicationLag": null,
"role": "HA",
"status": "ONLINE",
"version": "8.0.18"
},
"db3:3306": {
"address": "db3:3306",
"mode": "R/O",
"readReplicas": {},
"replicationLag": null,
"role": "HA",
"status": "ONLINE",
"version": "8.0.18"
}
},
"topologyMode": "Single-Primary"
},
"groupInformationSourceMember": "db2:3306"
}Mostra che db1 è ora disponibile ma servito come secondario con la sola lettura abilitata. Il ruolo principale è ancora assegnato a db2 fino a quando qualcosa non va storto nel nodo, dove verrà automaticamente eseguito il failover sul successivo nodo disponibile.
Verifica stato istanza
Possiamo controllare lo stato di un nodo MySQL prima di pianificare di aggiungerlo al cluster usando la funzione checkInstanceState(). Analizza i GTID eseguiti dall'istanza con i GTID eseguiti/eliminati sul cluster per determinare se l'istanza è valida per il cluster.
Quello che segue mostra lo stato dell'istanza di db3 quando era in modalità standalone, prima di parte del cluster:
MySQL|db1:3306 ssl|JS> cluster.checkInstanceState("db3:3306")
Cluster.checkInstanceState: The instance 'db3:3306' is a standalone instance but is part of a different InnoDB Cluster (metadata exists, instance does not belong to that metadata, and Group Replication is not active).Se il nodo fa già parte del cluster, dovresti ottenere quanto segue:
MySQL|db1:3306 ssl|JS> cluster.checkInstanceState("db3:3306")
Cluster.checkInstanceState: The instance 'db3:3306' already belongs to the ReplicaSet: 'default'.Monitoraggio di qualsiasi stato "interrogabile"
Con MySQL Shell, ora possiamo utilizzare il comando integrato \show e \watch per monitorare qualsiasi query amministrativa in tempo reale. Ad esempio, possiamo ottenere il valore in tempo reale dei thread collegati utilizzando:
MySQL|db1:3306 ssl|JS> \show query SHOW STATUS LIKE '%thread%';Oppure ottieni l'elenco di processi MySQL corrente:
MySQL|db1:3306 ssl|JS> \show query SHOW FULL PROCESSLISTPossiamo quindi utilizzare il comando \watch per eseguire un report allo stesso modo del comando \show, ma aggiorna i risultati a intervalli regolari finché non annulli il comando utilizzando Ctrl + C. Come mostrato in i seguenti esempi:
MySQL|db1:3306 ssl|JS> \watch query SHOW STATUS LIKE '%thread%';
MySQL|db1:3306 ssl|JS> \watch query --interval=1 SHOW FULL PROCESSLISTL'intervallo di aggiornamento predefinito è 2 secondi. Puoi modificare il valore utilizzando il flag --interval e specificando un valore compreso tra 0,1 e 86400.
Operazioni di gestione del cluster MySQL InnoDB
Commutazione primaria
L'istanza primaria è il nodo che può essere considerato il leader di un gruppo di replica, che ha la capacità di eseguire operazioni di lettura e scrittura. È consentita una sola istanza primaria per cluster in modalità topologia primaria singola. Questa topologia è anche nota come set di repliche ed è la modalità di topologia consigliata per la replica di gruppo con protezione contro i conflitti di blocco.
Per eseguire il passaggio all'istanza primaria, accedi a uno dei nodi del database come utente clusteradmin e specifica il nodo del database che desideri promuovere utilizzando la funzione setPrimaryInstance():
MySQL|db1:3306 ssl|JS> shell.connect("example@sqldat.com:3306");
MySQL|db1:3306 ssl|JS> cluster.setPrimaryInstance("db1:3306");
Setting instance 'db1:3306' as the primary instance of cluster 'my_innodb_cluster'...
Instance 'db2:3306' was switched from PRIMARY to SECONDARY.
Instance 'db3:3306' remains SECONDARY.
Instance 'db1:3306' was switched from SECONDARY to PRIMARY.
WARNING: The cluster internal session is not the primary member anymore. For cluster management operations please obtain a fresh cluster handle using <Dba>.getCluster().
The instance 'db1:3306' was successfully elected as primary.Abbiamo appena promosso db1 come nuovo componente primario, sostituendo db2 mentre db3 rimane come nodo secondario.
Chiusura del cluster
Il modo migliore per arrestare il cluster in modo corretto arrestando prima il servizio MySQL Router (se è in esecuzione) sul server delle applicazioni:
$ myrouter/stop.shIl passaggio precedente fornisce la protezione del cluster contro le scritture accidentali da parte delle applicazioni. Quindi spegni un nodo del database alla volta usando il comando di arresto MySQL standard o esegui lo spegnimento del sistema come desideri:
$ systemctl stop mysqlAvvio del cluster dopo uno spegnimento
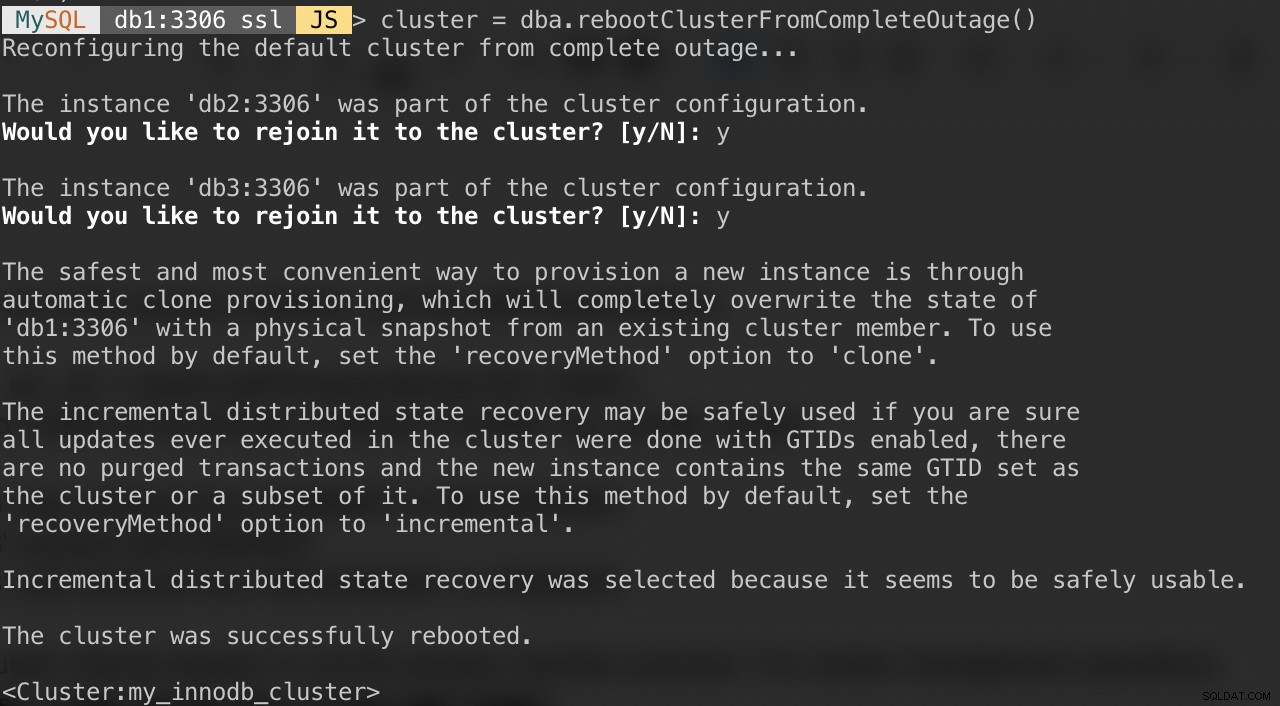
Se il tuo cluster soffre di un'interruzione completa o desideri avviare il cluster dopo un arresto pulito, puoi assicurarti che sia riconfigurato correttamente utilizzando la funzione dba.rebootClusterFromCompleteOutage(). Riporta semplicemente un cluster ONLINE quando tutti i membri sono OFFLINE. Nel caso in cui un cluster si sia arrestato completamente, le istanze devono essere avviate e solo allora il cluster può essere avviato.
Quindi, assicurati che tutti i server MySQL siano avviati e funzionanti. Su ogni nodo del database, controlla se il processo mysqld è in esecuzione:
$ ps -ef | grep -i mysqlQuindi, scegli un server di database come nodo principale e connettiti ad esso tramite la shell MySQL:
MySQL|JS> shell.connect("example@sqldat.com:3306");Esegui il seguente comando da quell'host per avviarli:
MySQL|db1:3306 ssl|JS> cluster = dba.rebootClusterFromCompleteOutage()Ti verranno presentate le seguenti domande:
Al termine di quanto sopra, puoi verificare lo stato del cluster:
MySQL|db1:3306 ssl|JS> cluster.status()A questo punto, db1 è il nodo primario e lo scrittore. Il resto saranno i membri secondari. Se desideri avviare il cluster con db2 o db3 come primario, puoi utilizzare la funzione shell.connect() per connetterti al nodo corrispondente ed eseguire rebootClusterFromCompleteOutage() da quel particolare nodo.
È quindi possibile avviare il servizio MySQL Router (se non è stato avviato) e consentire all'applicazione di connettersi nuovamente al cluster.
Impostazione delle opzioni di membri e cluster
Per ottenere le opzioni a livello di cluster, esegui semplicemente:
MySQL|db1:3306 ssl|JS> cluster.options()Quello sopra elencherà le opzioni globali per il set di repliche e anche le opzioni individuali per membro nel cluster. Questa funzione modifica un'opzione di configurazione del cluster InnoDB in tutti i membri del cluster. Le opzioni supportate sono:
- clusterName:valore stringa per definire il nome del cluster.
- exitStateAction:valore stringa che indica l'azione dello stato di uscita della replica del gruppo.
- memberWeight:valore intero con un peso percentuale per l'elezione primaria automatica in caso di failover.
- failoverConsistency:valore stringa che indica le garanzie di coerenza fornite dal cluster.
- coerenza: valore stringa che indica le garanzie di coerenza fornite dal cluster.
- expelTimeout:valore intero per definire il periodo di tempo in secondi che i membri del cluster devono attendere per un membro che non risponde prima di rimuoverlo dal cluster.
- autoRejoinTries:valore intero per definire il numero di volte in cui un'istanza tenterà di ricongiungersi al cluster dopo essere stata espulsa.
- disableClone:valore booleano utilizzato per disabilitare l'utilizzo del clone sul cluster.
Simile ad altre funzioni, l'output può essere filtrato nella struttura della mappa. Il comando seguente elencherà solo le opzioni per db2:
MySQL|db1:3306 ssl|JS> cluster.options().defaultReplicaSet.topology["db2:3306"]Puoi anche ottenere l'elenco sopra usando la funzione help():
MySQL|db1:3306 ssl|JS> cluster.help("setOption")Il comando seguente mostra un esempio per impostare un'opzione denominata memberWeight su 60 (da 50) su tutti i membri:
MySQL|db1:3306 ssl|JS> cluster.setOption("memberWeight", 60)
Setting the value of 'memberWeight' to '60' in all ReplicaSet members ...
Successfully set the value of 'memberWeight' to '60' in the 'default' ReplicaSet.Possiamo anche eseguire automaticamente la gestione della configurazione tramite MySQL Shell utilizzando la funzione setInstanceOption() e passare l'host del database, il nome dell'opzione e il valore di conseguenza:
MySQL|db1:3306 ssl|JS> cluster = dba.getCluster()
MySQL|db1:3306 ssl|JS> cluster.setInstanceOption("db1:3306", "memberWeight", 90)Le opzioni supportate sono:
- exitStateAction: valore stringa che indica l'azione dello stato di uscita della replica del gruppo.
- memberWeight:valore intero con un peso percentuale per l'elezione primaria automatica in caso di failover.
- autoRejoinTries:valore intero per definire il numero di volte in cui un'istanza tenterà di ricongiungersi al cluster dopo essere stata espulsa.
- etichetta un identificatore di stringa dell'istanza.
Passaggio alla modalità multiprimaria/singola primaria
Per impostazione predefinita, InnoDB Cluster è configurato con primario singolo, un solo membro in grado di eseguire letture e scritture contemporaneamente. Questo è il modo più sicuro e consigliato per eseguire il cluster e adatto alla maggior parte dei carichi di lavoro.
Tuttavia, se la logica dell'applicazione è in grado di gestire le scritture distribuite, è probabilmente una buona idea passare alla modalità multiprimaria, in cui tutti i membri del cluster sono in grado di elaborare letture e scritture contemporaneamente. Per passare dalla modalità singola primaria alla modalità multiprimaria, usa semplicemente la funzione switchToMultiPrimaryMode():
MySQL|db1:3306 ssl|JS> cluster.switchToMultiPrimaryMode()
Switching cluster 'my_innodb_cluster' to Multi-Primary mode...
Instance 'db2:3306' was switched from SECONDARY to PRIMARY.
Instance 'db3:3306' was switched from SECONDARY to PRIMARY.
Instance 'db1:3306' remains PRIMARY.
The cluster successfully switched to Multi-Primary mode.Verifica con:
MySQL|db1:3306 ssl|JS> cluster.status(){
"clusterName": "my_innodb_cluster",
"defaultReplicaSet": {
"name": "default",
"ssl": "REQUIRED",
"status": "OK",
"statusText": "Cluster is ONLINE and can tolerate up to ONE failure.",
"topology": {
"db1:3306": {
"address": "db1:3306",
"mode": "R/W",
"readReplicas": {},
"replicationLag": null,
"role": "HA",
"status": "ONLINE",
"version": "8.0.18"
},
"db2:3306": {
"address": "db2:3306",
"mode": "R/W",
"readReplicas": {},
"replicationLag": null,
"role": "HA",
"status": "ONLINE",
"version": "8.0.18"
},
"db3:3306": {
"address": "db3:3306",
"mode": "R/W",
"readReplicas": {},
"replicationLag": null,
"role": "HA",
"status": "ONLINE",
"version": "8.0.18"
}
},
"topologyMode": "Multi-Primary"
},
"groupInformationSourceMember": "db1:3306"
}In modalità multi-primaria, tutti i nodi sono primari e in grado di elaborare letture e scritture. Quando si invia una nuova connessione tramite MySQL Router sulla porta single-writer (6446), la connessione verrà inviata a un solo nodo, come in questo esempio db1:
(app-server)$ for i in {1..3}; do mysql -usbtest -p -h192.168.10.40 -P6446 -e 'select @@hostname, @@read_only, @@super_read_only'; done
+------------+-------------+-------------------+
| @@hostname | @@read_only | @@super_read_only |
+------------+-------------+-------------------+
| db1 | 0 | 0 |
+------------+-------------+-------------------+
+------------+-------------+-------------------+
| @@hostname | @@read_only | @@super_read_only |
+------------+-------------+-------------------+
| db1 | 0 | 0 |
+------------+-------------+-------------------+
+------------+-------------+-------------------+
| @@hostname | @@read_only | @@super_read_only |
+------------+-------------+-------------------+
| db1 | 0 | 0 |
+------------+-------------+-------------------+Se l'applicazione si connette alla porta multi-scrittore (6447), la connessione verrà bilanciata dal carico tramite l'algoritmo round robin a tutti i membri:
(app-server)$ for i in {1..3}; do mysql -usbtest -ppassword -h192.168.10.40 -P6447 -e 'select @@hostname, @@read_only, @@super_read_only'; done
+------------+-------------+-------------------+
| @@hostname | @@read_only | @@super_read_only |
+------------+-------------+-------------------+
| db2 | 0 | 0 |
+------------+-------------+-------------------+
+------------+-------------+-------------------+
| @@hostname | @@read_only | @@super_read_only |
+------------+-------------+-------------------+
| db3 | 0 | 0 |
+------------+-------------+-------------------+
+------------+-------------+-------------------+
| @@hostname | @@read_only | @@super_read_only |
+------------+-------------+-------------------+
| db1 | 0 | 0 |
+------------+-------------+-------------------+Come puoi vedere dall'output sopra, tutti i nodi sono in grado di elaborare letture e scritture con read_only =OFF. Puoi distribuire scritture sicure a tutti i membri connettendoti alla porta multi-scrittore (6447) e inviare le scritture in conflitto o pesanti alla porta single-writer (6446).
Per tornare alla modalità single-primary, utilizzare la funzione switchToSinglePrimaryMode() e specificare un membro come nodo primario. In questo esempio, abbiamo scelto db1:
MySQL|db1:3306 ssl|JS> cluster.switchToSinglePrimaryMode("db1:3306");
Switching cluster 'my_innodb_cluster' to Single-Primary mode...
Instance 'db2:3306' was switched from PRIMARY to SECONDARY.
Instance 'db3:3306' was switched from PRIMARY to SECONDARY.
Instance 'db1:3306' remains PRIMARY.
WARNING: Existing connections that expected a R/W connection must be disconnected, i.e. instances that became SECONDARY.
The cluster successfully switched to Single-Primary mode.A questo punto, db1 è ora il nodo primario configurato con sola lettura disabilitata e il resto sarà configurato come secondario con sola lettura abilitata.
Operazioni di ridimensionamento del cluster MySQL InnoDB
Ridimensionamento (aggiunta di un nuovo nodo DB)
Quando si aggiunge una nuova istanza, è necessario eseguire il provisioning di un nodo prima di poter partecipare al gruppo di replica. Il processo di provisioning sarà gestito automaticamente da MySQL. Inoltre, puoi controllare prima lo stato dell'istanza se il nodo è valido per unirsi al cluster utilizzando la funzione checkInstanceState() come spiegato in precedenza.
Per aggiungere un nuovo nodo DB, utilizza la funzione addInstances() e specifica l'host:
MySQL|db1:3306 ssl|JS> cluster.addInstance("db3:3306")Quanto segue è ciò che otterresti aggiungendo una nuova istanza:
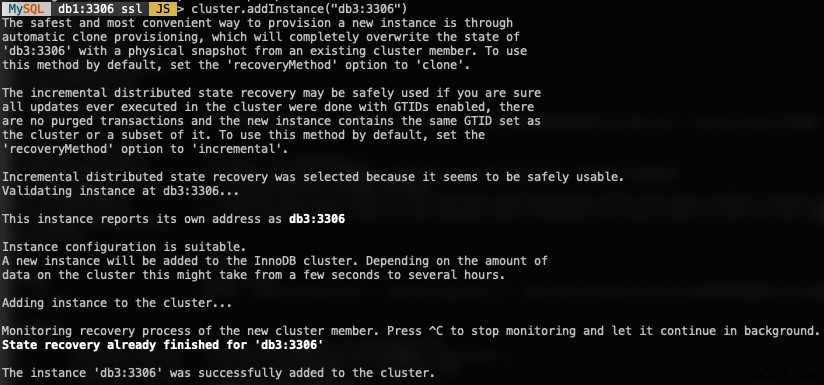
Verifica la nuova dimensione del cluster con:
MySQL|db1:3306 ssl|JS> cluster.status() //or cluster.describe()MySQL Router includerà automaticamente il nodo aggiunto, db3 nel set di bilanciamento del carico.
Ridimensionamento (rimozione di un nodo)
Per rimuovere un nodo, connettiti a uno qualsiasi dei nodi del database tranne quello che rimuoveremo e usa la funzione removeInstance() con il nome dell'istanza del database:
MySQL|db1:3306 ssl|JS> shell.connect("example@sqldat.com:3306");
MySQL|db1:3306 ssl|JS> cluster = dba.getCluster()
MySQL|db1:3306 ssl|JS> cluster.removeInstance("db3:3306")Quello che otterresti rimuovendo un'istanza:
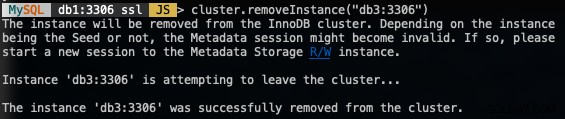
Verifica la nuova dimensione del cluster con:
MySQL|db1:3306 ssl|JS> cluster.status() //or cluster.describe()MySQL Router escluderà automaticamente il nodo rimosso, db3 dal set di bilanciamento del carico.
Aggiunta di un nuovo slave di replica
Possiamo scalare il cluster InnoDB con repliche slave di replica asincrona da qualsiasi nodo del cluster. Uno slave è accoppiato in modo lasco al cluster e sarà in grado di gestire un carico pesante senza influire sulle prestazioni del cluster. Lo slave può anche essere una copia live del database per scopi di ripristino di emergenza. In modalità multi-primaria, puoi utilizzare lo slave come processore MySQL di sola lettura dedicato per aumentare il carico di lavoro di lettura, eseguire operazioni di analisi o come server di backup dedicato.
Sul server slave, scarica l'ultimo pacchetto di configurazione APT, installalo (scegli MySQL 8.0 nella procedura guidata di configurazione), installa la chiave APT, aggiorna Repolist e installa il server MySQL.
$ wget https://repo.mysql.com/apt/ubuntu/pool/mysql-apt-config/m/mysql-apt-config/mysql-apt-config_0.8.14-1_all.deb
$ dpkg -i mysql-apt-config_0.8.14-1_all.deb
$ apt-key adv --recv-keys --keyserver ha.pool.sks-keyservers.net 5072E1F5
$ apt-get update
$ apt-get -y install mysql-server mysql-shellModificare il file di configurazione MySQL per preparare il server per la replica slave. Apri il file di configurazione tramite editor di testo:
$ vim /etc/mysql/mysql.conf.d/mysqld.cnfE aggiungi le seguenti righe:
server-id = 1044 # must be unique across all nodes
gtid-mode = ON
enforce-gtid-consistency = ON
log-slave-updates = OFF
read-only = ON
super-read-only = ON
expire-logs-days = 7Riavvia il server MySQL sullo slave per applicare le modifiche:
$ systemctl restart mysqlSu uno dei server InnoDB Cluster (abbiamo scelto db3), crea un utente slave di replica e seguito da un dump MySQL completo:
$ mysql -uroot -p
mysql> CREATE USER 'repl_user'@'192.168.0.44' IDENTIFIED BY 'password';
mysql> GRANT REPLICATION SLAVE ON *.* TO 'repl_user'@'192.168.0.44';
mysql> exit
$ mysqldump -uroot -p --single-transaction --master-data=1 --all-databases --triggers --routines --events > dump.sqlTrasferisci il file dump da db3 allo slave:
$ scp dump.sql example@sqldat.com:~Ed eseguire il ripristino sullo slave:
$ mysql -uroot -p < dump.sqlCon master-data=1, il nostro file di dump MySQL configurerà automaticamente il valore GTID eseguito ed eliminato. Possiamo verificarlo con la seguente istruzione sul server slave dopo il ripristino:
$ mysql -uroot -p
mysql> show global variables like '%gtid_%';
+----------------------------------+----------------------------------------------+
| Variable_name | Value |
+----------------------------------+----------------------------------------------+
| binlog_gtid_simple_recovery | ON |
| enforce_gtid_consistency | ON |
| gtid_executed | d4790339-0694-11ea-8fd5-02f67042125d:1-45886 |
| gtid_executed_compression_period | 1000 |
| gtid_mode | ON |
| gtid_owned | |
| gtid_purged | d4790339-0694-11ea-8fd5-02f67042125d:1-45886 |
+----------------------------------+----------------------------------------------+Sembra buono. Possiamo quindi configurare il collegamento di replica e avviare i thread di replica sullo slave:
mysql> CHANGE MASTER TO MASTER_HOST = '192.168.10.43', MASTER_USER = 'repl_user', MASTER_PASSWORD = 'password', MASTER_AUTO_POSITION = 1;
mysql> START SLAVE;Verifica lo stato di replica e assicurati che il seguente stato restituisca 'Sì':
mysql> show slave status\G
...
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
...A questo punto, la nostra architettura si presenta così:
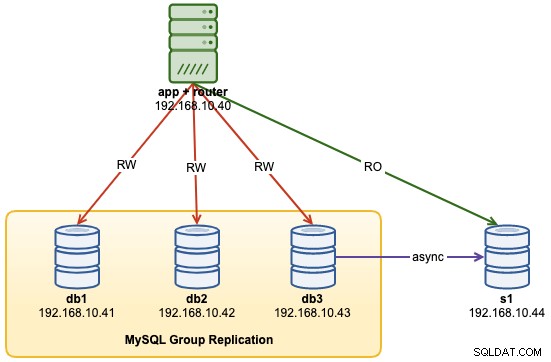
Problemi comuni con i cluster MySQL InnoDB
Esaurimento della memoria
Quando si utilizza MySQL Shell con MySQL 8.0, ricevevamo costantemente il seguente errore quando le istanze erano configurate con 1 GB di RAM:
Can't create a new thread (errno 11); if you are not out of available memory, you can consult the manual for a possible OS-dependent bug (MySQL Error 1135)L'aggiornamento della RAM di ciascun host a 2 GB di RAM ha risolto il problema. Apparentemente, i componenti di MySQL 8.0 richiedono più RAM per funzionare in modo efficiente.
Connessione persa al server MySQL
In case the primary node goes down, you would probably see the "lost connection to MySQL server error" when trying to query something on the current session:
MySQL|db1:3306 ssl|JS> cluster.status()
Cluster.status: Lost connection to MySQL server during query (MySQL Error 2013)
MySQL|db1:3306 ssl|JS> cluster.status()
Cluster.status: MySQL server has gone away (MySQL Error 2006)The solution is to re-declare the object once more:
MySQL|db1:3306 ssl|JS> cluster = dba.getCluster()
<Cluster:my_innodb_cluster>
MySQL|db1:3306 ssl|JS> cluster.status()At this point, it will connect to the newly promoted primary node to retrieve the cluster status.
Node Eviction and Expelled
In an event where communication between nodes is interrupted, the problematic node will be evicted from the cluster without any delay, which is not good if you are running on a non-stable network. This is what it looks like on db2 (the problematic node):
2019-11-14T07:07:59.344888Z 0 [ERROR] [MY-011505] [Repl] Plugin group_replication reported: 'Member was expelled from the group due to network failures, changing member status to ERROR.'
2019-11-14T07:07:59.371966Z 0 [ERROR] [MY-011712] [Repl] Plugin group_replication reported: 'The server was automatically set into read only mode after an error was detected.'Meanwhile from db1, it saw db2 was offline:
2019-11-14T07:07:44.086021Z 0 [Warning] [MY-011493] [Repl] Plugin group_replication reported: 'Member with address db2:3306 has become unreachable.'
2019-11-14T07:07:46.087216Z 0 [Warning] [MY-011499] [Repl] Plugin group_replication reported: 'Members removed from the group: db2:3306'
To tolerate a bit of delay on node eviction, we can set a higher timeout value before a node is being expelled from the group. The default value is 0, which means expel immediately. Use the setOption() function to set the expelTimeout value:
Thanks to Frédéric Descamps from Oracle who pointed this out:
Instead of relying on expelTimeout, it's recommended to set the autoRejoinTries option instead. The value represents the number of times an instance will attempt to rejoin the cluster after being expelled. A good number to start is 3, which means, the expelled member will try to rejoin the cluster for 3 times, which after an unsuccessful auto-rejoin attempt, the member waits 5 minutes before the next try.
To set this value cluster-wide, we can use the setOption() function:
MySQL|db1:3306 ssl|JS> cluster.setOption("autoRejoinTries", 3)
WARNING: Each cluster member will only proceed according to its exitStateAction if auto-rejoin fails (i.e. all retry attempts are exhausted).
Setting the value of 'autoRejoinTries' to '3' in all ReplicaSet members ...
Successfully set the value of 'autoRejoinTries' to '3' in the 'default' ReplicaSet.
Conclusione
For MySQL InnoDB Cluster, most of the management and monitoring operations can be performed directly via MySQL Shell (only available from MySQL 5.7.21 and later).