- In breve sulle tabelle pivot
- Pivoting dei dati tramite strumenti (dbForge Studio per MySQL)
- Pivot dei dati tramite SQL
- Esempio basato su T-SQL per SQL Server
- Esempio per MySQL
- Automatizzazione del pivot dei dati, creazione di query in modo dinamico
In breve sulle tabelle pivot
Questo articolo tratta della trasformazione dei dati della tabella da righe a colonne. Tale trasformazione è chiamata tabelle pivot. Spesso il risultato del pivot è una tabella riepilogativa in cui i dati statistici sono presentati nella forma adatta o richiesta per un report.
Inoltre, tale trasformazione dei dati può essere utile se un database non è normalizzato e le informazioni sono memorizzate in esso in una forma non ottimale. Pertanto, quando si riorganizza il database e si trasferiscono i dati a nuove tabelle o si genera una rappresentazione dei dati richiesta, il pivot dei dati può essere utile, ad esempio spostando i valori dalle righe alle colonne risultanti.
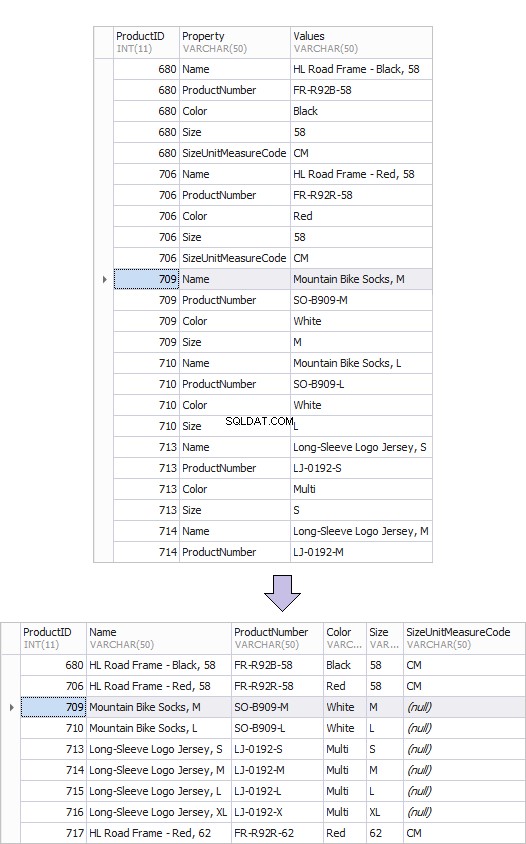
Di seguito è riportato un esempio della vecchia tabella dei prodotti - ProductsOld e di quella nuova - ProductsNew. È attraverso la trasformazione da righe a colonne che un tale risultato può essere facilmente ottenuto.
Ecco un esempio di tabella pivot.
Pivoting dei dati tramite strumenti (dbForge Studio per MySQL)
Esistono applicazioni che dispongono di strumenti che consentono di implementare data pivot in un comodo ambiente grafico. Ad esempio, dbForge Studio per MySQL include la funzionalità delle tabelle pivot che fornisce il risultato desiderato in pochi passaggi.

Diamo un'occhiata all'esempio con una tabella semplificata degli ordini:PurchaseOrderHeader .
CREATE TABLE PurchaseOrderHeader ( PurchaseOrderID INT(11) NOT NULL, EmployeeID INT(11) NOT NULL, VendorID INT(11) NOT NULL, PRIMARY KEY (PurchaseOrderID) ); INSERT PurchaseOrderHeader(PurchaseOrderID, EmployeeID, VendorID) VALUES (1, 258, 1580); INSERT PurchaseOrderHeader(PurchaseOrderID, EmployeeID, VendorID) VALUES (2, 254, 1496); INSERT PurchaseOrderHeader(PurchaseOrderID, EmployeeID, VendorID) VALUES (3, 257, 1494); INSERT PurchaseOrderHeader(PurchaseOrderID, EmployeeID, VendorID) VALUES (4, 261, 1650); INSERT PurchaseOrderHeader(PurchaseOrderID, EmployeeID, VendorID) VALUES (5, 251, 1654); INSERT PurchaseOrderHeader(PurchaseOrderID, EmployeeID, VendorID) VALUES (6, 253, 1664); INSERT PurchaseOrderHeader(PurchaseOrderID, EmployeeID, VendorID) VALUES (7, 255, 1678); INSERT PurchaseOrderHeader(PurchaseOrderID, EmployeeID, VendorID) VALUES (8, 256, 1616); INSERT PurchaseOrderHeader(PurchaseOrderID, EmployeeID, VendorID) VALUES (9, 259, 1492); INSERT PurchaseOrderHeader(PurchaseOrderID, EmployeeID, VendorID) VALUES (10, 250, 1602); INSERT PurchaseOrderHeader(PurchaseOrderID, EmployeeID, VendorID) VALUES (11, 258, 1540); ...
Si supponga di dover effettuare una selezione dalla tabella e determinare il numero di ordini effettuati da determinati dipendenti da fornitori specifici. L'elenco dei dipendenti per i quali sono necessarie informazioni:250, 251, 252, 253, 254.
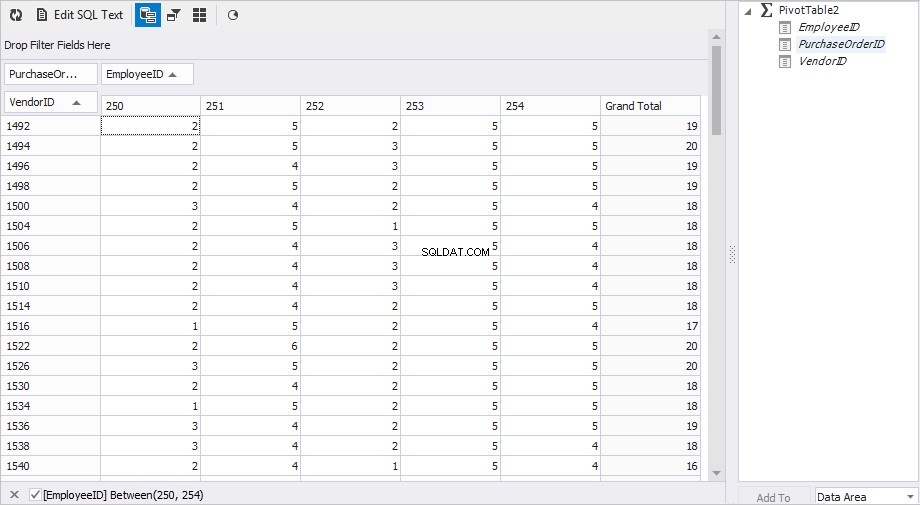
Una visualizzazione preferita per il rapporto è la seguente.
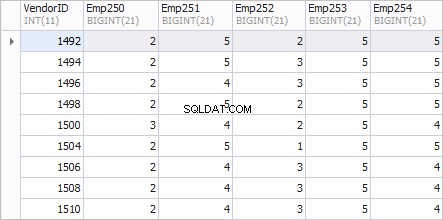
La colonna di sinistra VendorID mostra gli ID dei fornitori; colonne Emp250 , Emp251 , Emp252 , Emp253 e Emp254 visualizzare il numero di ordini.
Per raggiungere questo obiettivo in dbForge Studio per MySQL, devi:
- Aggiungi la tabella come origine dati per la rappresentazione "Tabella pivot" del documento. In Esplora database, fare clic con il pulsante destro del mouse su PurchaseOrderHeader tabella e seleziona Invia a e poi Tabella pivot nel menu a comparsa.
- Specificare una colonna i cui valori saranno righe. Trascina il ID fornitore colonna nella casella "Rilascia campi righe qui".
- Specificare una colonna i cui valori saranno colonne. Trascina l'ID dipendente colonna nella casella "Rilascia campi colonna qui". Puoi anche impostare un filtro per i dipendenti richiesti (250, 251, 252, 253, 254).
- Specificare una colonna, i cui valori saranno i dati. Trascina l'ID ordine di acquisto colonna nella casella "Rilascia elementi di dati qui".
- Nelle proprietà di PurchaseOrderID colonna, specifica il tipo di aggregazione – Conteggio valori .
Abbiamo rapidamente ottenuto il risultato di cui avevamo bisogno.
Pivot dei dati tramite SQL
Naturalmente, la trasformazione dei dati può essere eseguita tramite un database scrivendo una query SQL. Ma c'è un leggero intoppo, MySQL non ha un'istruzione specifica che lo consenta.
Esempio basato su T-SQL per SQL Server
Ad esempio, SqlServer e Oracle hanno l'operatore PIVOT che consente di effettuare tale trasformazione dei dati. Se lavorassimo con SqlServer, la nostra query sarebbe simile a questa.
SELECT
VendorID
,[250] AS Emp1
,[251] AS Emp2
,[252] AS Emp3
,[253] AS Emp4
,[254] AS Emp5
FROM (SELECT
PurchaseOrderID
,EmployeeID
,VendorID
FROM Purchasing.PurchaseOrderHeader) p
PIVOT
(
COUNT(PurchaseOrderID) FOR EmployeeID IN ([250], [251], [252], [253], [254])
) AS t
ORDER BY t.VendorID;
Esempio per MySQL
In MySQL, dovremo usare i mezzi di SQL. I dati devono essere raggruppati in base alla colonna del fornitore:VendorID e per ogni dipendente richiesto (EmployeeID ), è necessario creare una colonna separata con una funzione di aggregazione.
Nel nostro caso, dobbiamo calcolare il numero di ordini, quindi utilizzeremo la funzione aggregata COUNT.
Nella tabella di origine, le informazioni su tutti i dipendenti sono archiviate in una colonna EmployeeID e dobbiamo calcolare il numero di ordini per un determinato dipendente, quindi dobbiamo insegnare alla nostra funzione di aggregazione a elaborare solo determinate righe.
La funzione di aggregazione non tiene conto dei valori NULL e utilizziamo questa particolarità per i nostri scopi.
Puoi utilizzare l'operatore condizionale IF o CASE che restituirà un valore specifico per il dipendente desiderato, altrimenti restituirà semplicemente NULL; di conseguenza, la funzione COUNT conterà solo valori non NULL.
La query risultante è la seguente:
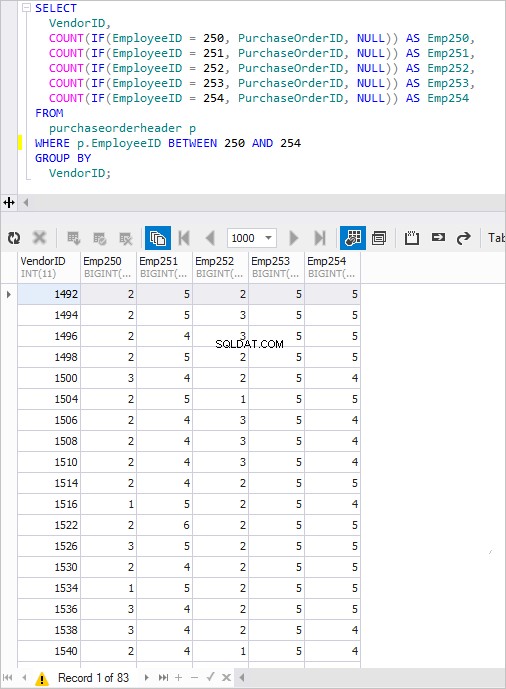
SELECT VendorID, COUNT(IF(EmployeeID = 250, PurchaseOrderID, NULL)) AS Emp250, COUNT(IF(EmployeeID = 251, PurchaseOrderID, NULL)) AS Emp251, COUNT(IF(EmployeeID = 252, PurchaseOrderID, NULL)) AS Emp252, COUNT(IF(EmployeeID = 253, PurchaseOrderID, NULL)) AS Emp253, COUNT(IF(EmployeeID = 254, PurchaseOrderID, NULL)) AS Emp254 FROM PurchaseOrderHeader p WHERE p.EmployeeID BETWEEN 250 AND 254 GROUP BY VendorID;
O anche così:
VendorID, COUNT(IF(EmployeeID = 250, 1, NULL)) AS Emp250, COUNT(IF(EmployeeID = 251, 1, NULL)) AS Emp251, COUNT(IF(EmployeeID = 252, 1, NULL)) AS Emp252, COUNT(IF(EmployeeID = 253, 1, NULL)) AS Emp253, COUNT(IF(EmployeeID = 254, 1, NULL)) AS Emp254 FROM PurchaseOrderHeader p WHERE p.EmployeeID BETWEEN 250 AND 254 GROUP BY VendorID;
Quando viene eseguito, si ottiene un risultato familiare.
Automatizzazione del pivot dei dati, creazione dinamica di query
Come si vede, la query ha una certa consistenza, ovvero tutte le colonne trasformate sono formate in modo simile, e per scrivere la query è necessario conoscere i valori specifici della tabella. Per formare una query pivot, devi rivedere tutti i valori possibili e solo allora dovresti scrivere la query. In alternativa, puoi passare questa attività a un server in modo che ottenga questi valori ed esegua dinamicamente l'attività di routine.
Torniamo al primo esempio, in cui abbiamo formato la nuova tabella ProductsNew da ProductsOld tavolo. Lì, i valori delle proprietà sono limitati e non possiamo nemmeno conoscere tutti i valori possibili; abbiamo solo le informazioni su dove sono memorizzati i nomi delle proprietà e il loro valore. Queste sono le Proprietà e Valore colonne, rispettivamente.
L'intero algoritmo di creazione della query SQL si riduce all'ottenimento dei valori, da cui verranno formate nuove colonne e concatenazioni di parti non modificabili della query.
SELECT
GROUP_CONCAT(
CONCAT(
' MAX(IF(Property = ''',
t.Property,
''', Value, NULL)) AS ',
t.Property
)
) INTO @PivotQuery
FROM
(SELECT
Property
FROM
ProductOld
GROUP BY
Property) t;
SET @PivotQuery = CONCAT('SELECT ProductID,', @PivotQuery, ' FROM ProductOld GROUP BY ProductID');
La variabile @PivotQuery memorizzerà la nostra query, il testo è stato formattato per chiarezza.
SELECT ProductID, MAX(IF(Property = 'Color', Value, NULL)) AS Color, MAX(IF(Property = 'Name', Value, NULL)) AS Name, MAX(IF(Property = 'ProductNumber', Value, NULL)) AS ProductNumber, MAX(IF(Property = 'Size', Value, NULL)) AS Size, MAX(IF(Property = 'SizeUnitMeasureCode', Value, NULL)) AS SizeUnitMeasureCode FROM ProductOld GROUP BY ProductID
Dopo averlo eseguito, otterremo il risultato desiderato corrispondente allo schema della tabella ProductsNew.
Inoltre, la query dalla variabile @PivotQuery può essere eseguita nello script utilizzando l'istruzione MySQL EXECUTE.
PREPARE statement FROM @PivotQuery; EXECUTE statement; DEALLOCATE PREPARE statement;