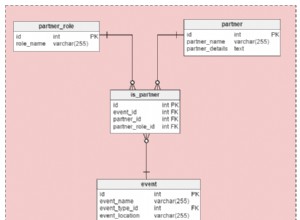
Trovo piuttosto più semplice specificare gli insiemi esatti di cui ho bisogno con la clausola GROUPING SET:
WITH data(val1, val2, val3) AS
( SELECT 'a' ,'a-details' ,'1' FROM DUAL
UNION ALL
SELECT 'b' ,'b-details' ,'2' FROM DUAL
UNION ALL
SELECT 'c' ,'c-details' ,'3' FROM DUAL
)
SELECT NVL(val1,'Total Result'),
val2,
SUM(val3) tot
from data
group by grouping sets ((val1, val2),());
Sospetto che sia più efficiente, poiché specifica direttamente i livelli da calcolare.
https://sqlfiddle.com/#!4/8301d/3
CUBE e ROLLUP sono utili per generare automaticamente un numero elevato di livelli di aggregazione (ad es. ogni livello in una gerarchia dimensionale) e potrebbe essere opportuno utilizzare GROUPING ID se si desidera eliminare un piccolo sottoinsieme di livelli da un grande CUBE generato set, ma GROUPING SET è progettato precisamente per specificare livelli di aggregazione particolari.