Se dovessi avere un massiccio problemi con il tuo approccio, molto probabilmente ti manca un indice nella colonna clean.id , necessario per il tuo approccio quando MERGE utilizza dual come fonte per ogni riga.
Questo è meno probabile mentre dici l'id è una chiave primaria .
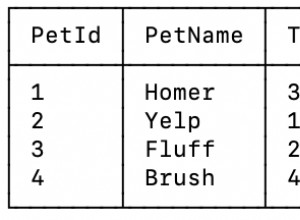
Quindi fondamentalmente stai pensando nel modo giusto e vedrai il piano di esecuzione simile a quello qui sotto:
---------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------------------------------
| 0 | MERGE STATEMENT | | | | 2 (100)| |
| 1 | MERGE | CLEAN | | | | |
| 2 | VIEW | | | | | |
| 3 | NESTED LOOPS OUTER | | 1 | 40 | 2 (0)| 00:00:01 |
| 4 | TABLE ACCESS FULL | DUAL | 1 | 2 | 2 (0)| 00:00:01 |
| 5 | VIEW | VW_LAT_A18161FF | 1 | 38 | 0 (0)| |
| 6 | TABLE ACCESS BY INDEX ROWID| CLEAN | 1 | 38 | 0 (0)| |
|* 7 | INDEX UNIQUE SCAN | CLEAN_UX1 | 1 | | 0 (0)| |
---------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
7 - access("CLEAN"."ID"=:ID)
Quindi il piano di esecuzione va bene e funziona in modo efficace, ma presenta un problema.
Ricorda usa sempre un indice, sarai felice mentre elabori poche righe, ma non verrà ridimensionato .
Se stai elaborando milioni di record, potresti ricorrere a un'elaborazione in due fasi,
-
inserisci tutte le righe in una tabella temporanea
-
eseguire un singolo
MERGEistruzione utilizzando la tabella temporanea
Il grande vantaggio è che Oracle può aprire un hash join ed elimina l'accesso all'indice per ciascuno dei milioni righe.
Ecco un esempio di un test di clean tabella iniziata con 1M id (non mostrato) ed eseguendo 1M di inserimento e 1M di aggiornamenti:
n = 1000000
data2 = [{"id" : i, "xcount" :1} for i in range(2*n)]
sql3 = """
insert into tmp (id,count)
values (:id,:xcount)"""
sql4 = """MERGE into clean USING tmp on (clean.id = tmp.id)
when not matched then insert (id, count) values (tmp.id, tmp.count)
when matched then update set clean.count= clean.count + tmp.count"""
cursor.executemany(sql3, data2)
cursor.execute(sql4)
Il test viene eseguito in ca. 10 secondi, che è meno della metà di te che ti avvicini con MERGE usando dual .
Se questo non è ancora sufficiente, dovrai utilizzare l'opzione parallela .